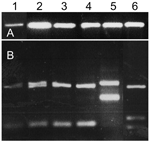
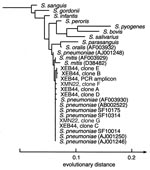
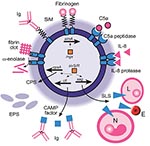
Operón
Operón de ARNr
Regulación Bacteriana de la Expresión Génica
Operón Lac
Escherichia coli
Datos de Secuencia Molecular
Secuencia de Bases
Transcripción Genética
ARN Bacteriano
Regiones Promotoras Genéticas
Genes Reguladores
Secuencia de Aminoácidos
Clonación Molecular
Mutación
Mapeo Restrictivo
Prueba de Complementación Genética
Proteínas Represoras
Mutagénesis Insercional
Análisis de Secuencia de ADN
beta-Galactosidasa
Salmonella typhimurium
Cromosomas Bacterianos
Familia de Multigenes
Elementos Transponibles de ADN
Mapeo Cromosómico
Sistemas de Lectura Abierta
Regulón
Represión Enzimática
Factor sigma
Genes
Homología de Secuencia de Aminoácido
Fusión Artificial Génica
Homología de Secuencia de Ácido Nucleico
Regiones Terminadoras Genéticas
Regiones Operadoras Genéticas
Arabinosa
Pseudomonas putida
Triptofanasa
Factores de Transcripción
Eliminación de Gen
Proteínas de Unión al ADN
Virulencia
Triptófano
Proteína Reguladora de Respuesta a la Leucina
ARN Polimerasas Dirigidas por ADN
Conformación de Ácido Nucleico
Alineación de Secuencia
Enzimas de Restricción del ADN
Anaerobiosis
Escherichia coli K12
Un operón es una unidad funcional de la transcripción en prokaryotes, que consiste en uno o más genes adyacentes controlados por un solo promotor y terminador, y a menudo un solo sitio de operador entre ellos. Los genes dentro de un operón están relacionados funcionalmente y se transcriben juntos como un ARN mensajero polcistronico, el cual luego es traducido en múltiples proteínas. Este mecanismo permite la regulación coordinada de la expresión génica de los genes relacionados. El concepto de operón fue introducido por Jacob y Monod en 1961 para explicar la regulación genética en Escherichia coli. Los ejemplos bien conocidos de operones incluyen el operón lac, que controla la digestión de lactosa, y el operón trp, que regula la biosíntesis de triptófano. En eukaryotes, los genes suelen estar dispuestos individualmente y no tienen operones como se definen en prokaryotes.
Un operón de ARNr es una unidad funcional de transcripción en el ADN de los procariotas que consiste en genes que codifican para diferentes subunidades del ARN ribosomal (ARNr). Los genes de ARNr se transcriben juntos como un solo transcrito grande, seguido de procesamiento adicional para producir las moléculas de ARNr maduras. Este mecanismo permite la coordinación temporal y cuantitativa de la expresión génica de los componentes del ribosoma, lo que facilita la eficiente síntesis de proteínas en procariotas.
La regulación bacteriana de la expresión génica se refiere al proceso por el cual las bacterias controlan la activación y desactivación de los genes para producir proteínas específicas en respuesta a diversos estímulos ambientales. Este mecanismo permite a las bacterias adaptarse rápidamente a cambios en su entorno, como la disponibilidad de nutrientes, la presencia de compuestos tóxicos o la existencia de otros organismos competidores.
La regulación de la expresión génica en bacterias implica principalmente el control de la transcripción, que es el primer paso en la producción de proteínas a partir del ADN. La transcripción está catalizada por una enzima llamada ARN polimerasa, que copia el código genético contenido en los genes (secuencias de ADN) en forma de moléculas de ARN mensajero (ARNm). Posteriormente, este ARNm sirve como plantilla para la síntesis de proteínas mediante el proceso de traducción.
Existen diversos mecanismos moleculares involucrados en la regulación bacteriana de la expresión génica, incluyendo:
1. Control operonal: Consiste en la regulación coordinada de un grupo de genes relacionados funcionalmente, llamado operón, mediante la unión de factores de transcripción a regiones reguladoras específicas del ADN. Un ejemplo bien conocido es el operón lac, involucrado en el metabolismo de lactosa en Escherichia coli.
2. Control de iniciación de la transcripción: Implica la interacción entre activadores o represores de la transcripción y la ARN polimerasa en el sitio de iniciación de la transcripción, afectando así la unión o desplazamiento de la ARN polimerasa del promotor.
3. Control de terminación de la transcripción: Consiste en la interrupción prematura de la transcripción mediante la formación de estructuras secundarias en el ARNm o por la unión de factores que promueven la disociación de la ARN polimerasa del ADN.
4. Modulación postraduccional: Afecta la estabilidad, actividad o localización de las proteínas mediante modificaciones químicas, como fosforilación, acetilación o ubiquitinación, después de su síntesis.
La comprensión de los mecanismos moleculares implicados en la regulación bacteriana de la expresión génica es fundamental para el desarrollo de estrategias terapéuticas y tecnológicas, como la ingeniería metabólica o la biotecnología.
El operón lac es un sistema genético encontrado en la bacteria Escherichia coli y algunas otras bacterias, que controla la transcripción y traducción coordinadas de varios genes relacionados con el metabolismo del azúcar lactosa. El término "operón" se refiere a un grupo de genes adyacentes en el cromosoma bacteriano que están controlados por un solo promotor y un operador, y son transcritos juntos como un único ARN mensajero policistrónico.
El operón lac consta de tres genes estructurales (lacZ, lacY, y lacA) y dos genes reguladores (lacI y lacO). El gen lacI codifica para la proteína represora, que se une al operador lacO para impedir la transcripción de los genes estructurales. Cuando la lactosa está disponible como fuente de carbono, un cofactor llamado alolactosa se une a la proteína represora y la inactiva, permitiendo que el ARN polimerasa se una al promotor y comience la transcripción de los genes estructurales.
El gen lacZ codifica para la β-galactosidasa, una enzima que escinde la lactosa en glucosa y galactosa. El gen lacY codifica para el transportador de lactosa, que permite que la lactosa ingrese a la célula bacteriana. Por último, el gen lacA codifica para la transacetilasa de lactosa, una enzima que modifica químicamente la lactosa después de su transporte al interior de la célula.
En resumen, el operón lac es un sistema genético regulado que permite a las bacterias utilizar la lactosa como fuente de energía y carbono cuando otras fuentes de nutrientes son limitadas.
En términos médicos, los genes bacterianos se refieren a los segmentos específicos del material genético (ADN o ARN) que contienen la información hereditaria en las bacterias. Estos genes desempeñan un papel crucial en la determinación de las características y funciones de una bacteria, incluyendo su crecimiento, desarrollo, supervivencia y reproducción.
Los genes bacterianos están organizados en cromosomas bacterianos, que son generalmente círculos de ADN de doble hebra, aunque algunas bacterias pueden tener más de un cromosoma. Además de los cromosomas bacterianos, las bacterias también pueden contener plásmidos, que son pequeños anillos de ADN de doble o simple hebra que pueden contener uno o más genes y pueden ser transferidos entre bacterias mediante un proceso llamado conjugación.
Los genes bacterianos codifican para una variedad de productos genéticos, incluyendo enzimas, proteínas estructurales, factores de virulencia y moléculas de señalización. El estudio de los genes bacterianos y su función es importante para comprender la biología de las bacterias, así como para el desarrollo de estrategias de diagnóstico y tratamiento de enfermedades infecciosas causadas por bacterias.
Las proteínas bacterianas se refieren a las diversas proteínas que desempeñan varios roles importantes en el crecimiento, desarrollo y supervivencia de las bacterias. Estas proteínas son sintetizadas por los propios organismos bacterianos y están involucradas en una amplia gama de procesos biológicos, como la replicación del ADN, la transcripción y traducción de genes, el metabolismo, la respuesta al estrés ambiental, la adhesión a superficies y la formación de biofilms, entre otros.
Algunas proteínas bacterianas también pueden desempeñar un papel importante en la patogenicidad de las bacterias, es decir, su capacidad para causar enfermedades en los huéspedes. Por ejemplo, las toxinas y enzimas secretadas por algunas bacterias patógenas pueden dañar directamente las células del huésped y contribuir al desarrollo de la enfermedad.
Las proteínas bacterianas se han convertido en un área de intenso estudio en la investigación microbiológica, ya que pueden utilizarse como objetivos para el desarrollo de nuevos antibióticos y otras terapias dirigidas contra las infecciones bacterianas. Además, las proteínas bacterianas también se utilizan en una variedad de aplicaciones industriales y biotecnológicas, como la producción de enzimas, la fabricación de alimentos y bebidas, y la biorremediación.
"Escherichia coli" (abreviado a menudo como "E. coli") es una especie de bacterias gram-negativas, anaerobias facultativas, en forma de bastón, perteneciente a la familia Enterobacteriaceae. Es parte de la flora normal del intestino grueso humano y de muchos animales de sangre caliente. Sin embargo, ciertas cepas de E. coli pueden causar diversas infecciones en humanos y otros mamíferos, especialmente si ingresan a otras partes del cuerpo donde no pertenecen, como el sistema urinario o la sangre. Las cepas patógenas más comunes de E. coli causan gastroenteritis, una forma de intoxicación alimentaria. La cepa O157:H7 es bien conocida por provocar enfermedades graves, incluidas insuficiencia renal y anemia hemolítica microangiopática. Las infecciones por E. coli se pueden tratar con antibióticos, pero las cepas resistentes a los medicamentos están aumentando en frecuencia. La prevención generalmente implica prácticas de higiene adecuadas, como lavarse las manos y cocinar bien la carne.
Los Datos de Secuencia Molecular se refieren a la información detallada y ordenada sobre las unidades básicas que componen las moléculas biológicas, como ácidos nucleicos (ADN y ARN) y proteínas. Esta información está codificada en la secuencia de nucleótidos en el ADN o ARN, o en la secuencia de aminoácidos en las proteínas.
En el caso del ADN y ARN, los datos de secuencia molecular revelan el orden preciso de las cuatro bases nitrogenadas: adenina (A), timina/uracilo (T/U), guanina (G) y citosina (C). La secuencia completa de estas bases proporciona información genética crucial que determina la función y la estructura de genes y proteínas.
En el caso de las proteínas, los datos de secuencia molecular indican el orden lineal de los veinte aminoácidos diferentes que forman la cadena polipeptídica. La secuencia de aminoácidos influye en la estructura tridimensional y la función de las proteínas, por lo que es fundamental para comprender su papel en los procesos biológicos.
La obtención de datos de secuencia molecular se realiza mediante técnicas experimentales especializadas, como la reacción en cadena de la polimerasa (PCR), la secuenciación de ADN y las técnicas de espectrometría de masas. Estos datos son esenciales para la investigación biomédica y biológica, ya que permiten el análisis de genes, genomas, proteínas y vías metabólicas en diversos organismos y sistemas.
La secuencia de bases, en el contexto de la genética y la biología molecular, se refiere al orden específico y lineal de los nucleótidos (adenina, timina, guanina y citosina) en una molécula de ADN. Cada tres nucleótidos representan un codón que especifica un aminoácido particular durante la traducción del ARN mensajero a proteínas. Por lo tanto, la secuencia de bases en el ADN determina la estructura y función de las proteínas en un organismo. La determinación de la secuencia de bases es una tarea central en la genómica y la biología molecular moderna.
La transcripción genética es un proceso bioquímico fundamental en la biología, donde el ADN (ácido desoxirribonucleico), el material genético de un organismo, se utiliza como plantilla para crear una molécula complementaria de ARN (ácido ribonucleico). Este proceso es crucial porque el ARN producido puede servir como molde para la síntesis de proteínas en el proceso de traducción, o puede desempeñar otras funciones importantes dentro de la célula.
El proceso específico de la transcripción genética implica varias etapas: iniciación, elongación y terminación. Durante la iniciación, la ARN polimerasa, una enzima clave, se une a la secuencia promotora del ADN, un área específica del ADN que indica dónde comenzar la transcripción. La hélice de ADN se desenvuelve y se separa para permitir que la ARN polimerasa lea la secuencia de nucleótidos en la hebra de ADN y comience a construir una molécula complementaria de ARN.
En la etapa de elongación, la ARN polimerasa continúa agregando nucleótidos al extremo 3' de la molécula de ARN en crecimiento, usando la hebra de ADN como plantilla. La secuencia de nucleótidos en el ARN es complementaria a la hebra de ADN antisentido (la hebra que no se está transcripción), por lo que cada A en el ADN se empareja con un U en el ARN (en lugar del T encontrado en el ADN), mientras que los G, C y Ts del ADN se emparejan con las respectivas C, G y As en el ARN.
Finalmente, durante la terminación, la transcripción se detiene cuando la ARN polimerasa alcanza una secuencia específica de nucleótidos en el ADN que indica dónde terminar. La molécula recién sintetizada de ARN se libera y procesada adicionalmente, si es necesario, antes de ser utilizada en la traducción o cualquier otro proceso celular.
El ADN bacteriano se refiere al material genético presente en las bacterias, que están compuestas por una única molécula de ADN circular y de doble hebra. Este ADN contiene todos los genes necesarios para la supervivencia y reproducción de la bacteria, así como información sobre sus características y comportamiento.
La estructura del ADN bacteriano es diferente a la del ADN presente en células eucariotas (como las de animales, plantas y hongos), que generalmente tienen múltiples moléculas de ADN lineal y de doble hebra contenidas dentro del núcleo celular.
El ADN bacteriano también puede contener plásmidos, que son pequeñas moléculas de ADN circular adicionales que pueden conferir a la bacteria resistencia a antibióticos u otras características especiales. Los plásmidos pueden ser transferidos entre bacterias a través de un proceso llamado conjugación, lo que puede contribuir a la propagación de genes resistentes a los antibióticos y otros rasgos indeseables en poblaciones bacterianas.
Las proteínas de Escherichia coli (E. coli) se refieren a las diversas proteínas producidas por la bacteria gram-negativa E. coli, que es un organismo modelo comúnmente utilizado en estudios bioquímicos y genéticos. Este microorganismo posee una gama amplia y bien caracterizada de proteínas, las cuales desempeñan diversas funciones vitales en su crecimiento, supervivencia y patogenicidad. Algunas de estas proteínas están involucradas en la replicación del ADN, la transcripción, la traducción, el metabolismo, el transporte de nutrientes, la respuesta al estrés y la formación de la pared celular y la membrana.
Un ejemplo notable de proteína producida por E. coli es la toxina Shiga, que se asocia con ciertas cepas patógenas de esta bacteria y puede causar enfermedades graves en humanos, como diarrea hemorrágica y síndrome urémico hemolítico. Otra proteína importante es la β-galactosidasa, que se utiliza a menudo como un marcador reportero en experimentos genéticos para medir los niveles de expresión génica.
El estudio y la caracterización de las proteínas de E. coli han contribuido significativamente al avance de nuestra comprensión de la biología celular, la bioquímica y la genética, y siguen siendo un área de investigación activa en la actualidad.
El ARN bacteriano se refiere al ácido ribonucleico que se encuentra en las bacterias. Los bacterias no tienen un núcleo celular y, por lo tanto, sus ARN (ácidos ribonucleicos) están presentes en el citoplasma celular. Existen tres tipos principales de ARN bacterianos: ARN mensajero (mARN), ARN de transferencia (tARN) y ARN ribosomal (rARN). Estos ARN desempeñan un papel crucial en la transcripción, traducción y síntesis de proteínas en las bacterias. El ARN bacteriano es a menudo el objetivo de antibióticos que inhiben la síntesis de proteínas y, por lo tanto, la supervivencia bacteriana.
*Nota: Aunque soy un experto en IA, no soy un médico. La siguiente información ha sido investigada y compilada a partir de fuentes médicas y científicas confiables, pero si necesita información médica precisa, consulte a un profesional médico.*
*Bacillus subtilis* es una bacteria grampositiva, aerobia o anaerobia facultativa, comúnmente encontrada en el suelo y en el tracto gastrointestinal de los animales de vida libre y domésticos. Es un bacilo grande, generalmente con forma de varilla, que puede formar endosporas resistentes a la desecación y a las temperatururas extremas. Las esporas de *B. subtilis* son ampliamente distribuidas en el ambiente y pueden sobrevivir durante largos períodos en condiciones adversas.
Aunque *B. subtilis* se considera una bacteria generalmente no patogénica, ha habido informes aislados de infecciones humanas, particularmente en individuos inmunocomprometidos o con dispositivos médicos internos. Las infecciones pueden incluir bacteriemia, endocarditis, meningitis y abscesos.
En la medicina y la investigación, *B. subtilis* se utiliza a menudo como organismo modelo debido a su fácil cultivo, rápido crecimiento y capacidad de formar esporas. También se ha estudiado por sus posibles usos en biotecnología, como la producción de enzimas industriales y la biodegradación de contaminantes ambientales.
En resumen, *Bacillus subtilis* es una bacteria comúnmente encontrada en el suelo y en animales, generalmente no patogénica para los humanos, pero con potencial de causar infecciones en individuos inmunocomprometidos. Se utiliza ampliamente en la investigación médica y biotecnológica.
Las regiones promotoras genéticas, también conocidas como regiones reguladorias cis o elementos enhancer, son segmentos específicos del ADN que desempeñan un papel crucial en la regulación de la transcripción génica. Esencialmente, actúan como interruptores que controlan cuándo, dónde y en qué cantidad se produce un gen determinado.
Estas regiones contienen secuencias reconocidas por proteínas reguladoras, llamadas factores de transcripción, que se unen a ellas e interactúan con la maquinaria molecular necesaria para iniciar la transcripción del ADN en ARN mensajero (ARNm). Los cambios en la actividad o integridad de estas regiones promotoras pueden dar lugar a alteraciones en los niveles de expresión génica, lo que a su vez puede conducir a diversos fenotipos y posiblemente a enfermedades genéticas.
Es importante destacar que las mutaciones en las regiones promotoras genéticas pueden tener efectos más sutiles pero extendidos en comparación con las mutaciones en el propio gen, ya que afectan a la expresión de múltiples genes regulados por esa región promovedora particular. Por lo tanto, comprender las regiones promotoras y su regulación es fundamental para entender los mecanismos moleculares detrás de la expresión génica y las enfermedades asociadas con su disfunción.
Los genes reguladores son un tipo de gen que codifican proteínas involucradas en la regulación de la expresión génica, es decir, en el proceso por el cual el material genético se transforma en productos funcionales. Estas proteínas, llamadas factores de transcripción, se unen a secuencias específicas del ADN y controlan la tasa de transcripción de los genes diana, determinando así cuánto y cuándo se producirá una proteína en particular. Los genes reguladores desempeñan un papel crucial en el desarrollo, la diferenciación celular y la homeostasis de los organismos. La alteración en la actividad de estos genes puede conducir a diversas enfermedades, incluyendo cáncer y trastornos genéticos.
La secuencia de aminoácidos se refiere al orden específico en que los aminoácidos están unidos mediante enlaces peptídicos para formar una proteína. Cada proteína tiene su propia secuencia única, la cual es determinada por el orden de los codones (secuencias de tres nucleótidos) en el ARN mensajero (ARNm) que se transcribe a partir del ADN.
Las cadenas de aminoácidos pueden variar en longitud desde unos pocos aminoácidos hasta varios miles. El plegamiento de esta larga cadena polipeptídica y la interacción de diferentes regiones de la misma dan lugar a la estructura tridimensional compleja de las proteínas, la cual desempeña un papel crucial en su función biológica.
La secuencia de aminoácidos también puede proporcionar información sobre la evolución y la relación filogenética entre diferentes especies, ya que las regiones conservadas o similares en las secuencias pueden indicar una ascendencia común o una función similar.
La clonación molecular es un proceso de laboratorio que crea copias idénticas de fragmentos de ADN. Esto se logra mediante la utilización de una variedad de técnicas de biología molecular, incluyendo la restricción enzimática, ligación de enzimas y la replicación del ADN utilizando la polimerasa del ADN (PCR).
La clonación molecular se utiliza a menudo para crear múltiples copias de un gen o fragmento de interés, lo que permite a los científicos estudiar su función y estructura. También se puede utilizar para producir grandes cantidades de proteínas específicas para su uso en la investigación y aplicaciones terapéuticas.
El proceso implica la creación de un vector de clonación, que es un pequeño círculo de ADN que puede ser replicado fácilmente dentro de una célula huésped. El fragmento de ADN deseado se inserta en el vector de clonación utilizando enzimas de restricción y ligasa, y luego se introduce en una célula huésped, como una bacteria o levadura. La célula huésped entonces replica su propio ADN junto con el vector de clonación y el fragmento de ADN insertado, creando así copias idénticas del fragmento original.
La clonación molecular es una herramienta fundamental en la biología molecular y ha tenido un gran impacto en la investigación genética y biomédica.
En términos médicos, una mutación se refiere a un cambio permanente y hereditable en la secuencia de nucleótidos del ADN (ácido desoxirribonucleico) que puede ocurrir de forma natural o inducida. Esta alteración puede afectar a uno o más pares de bases, segmentos de DNA o incluso intercambios cromosómicos completos.
Las mutaciones pueden tener diversos efectos sobre la función y expresión de los genes, dependiendo de dónde se localicen y cómo afecten a las secuencias reguladoras o codificantes. Algunas mutaciones no producen ningún cambio fenotípico visible (silenciosas), mientras que otras pueden conducir a alteraciones en el desarrollo, enfermedades genéticas o incluso cancer.
Es importante destacar que existen diferentes tipos de mutaciones, como por ejemplo: puntuales (sustituciones de una base por otra), deletérreas (pérdida de parte del DNA), insercionales (adición de nuevas bases al DNA) o estructurales (reordenamientos más complejos del DNA). Todas ellas desempeñan un papel fundamental en la evolución y diversidad biológica.
El término "mapeo restrictivo" no es un término médico ampliamente utilizado o reconocido en la literatura médica o científica. Sin embargo, en algunos contextos específicos y limitados, particularmente en el campo de la genética y la bioinformática, "mapeo restrictivo" puede referirse al proceso de asignar secuencias de ADN a regiones específicas del genoma utilizando una cantidad limitada o "restrictiva" de enzimas de restricción.
Las enzimas de restricción son endonucleasas que cortan el ADN en sitios específicos de secuencia. El mapeo restrictivo implica el uso de un pequeño número de estas enzimas para determinar la ubicación de las secuencias de ADN desconocidas dentro del genoma. Este enfoque puede ser útil en situaciones en las que se dispone de información limitada sobre la secuencia o la estructura del genoma, y puede ayudar a identificar regiones específicas del ADN para un análisis más detallado.
Sin embargo, es importante tener en cuenta que el "mapeo restrictivo" no es una técnica o concepto médico ampliamente utilizado o reconocido, y su uso puede variar dependiendo del contexto específico y la especialidad de la investigación.
La prueba de complementación genética es un tipo de prueba de laboratorio utilizada en genética molecular para determinar si dos genes mutantes que causan la misma enfermedad en diferentes individuos son defectivos en la misma función génica o no. La prueba implica la combinación de material genético de los dos individuos y el análisis de si la función genética se restaura o no.
En esta prueba, se crean células híbridas al fusionar las células que contienen cada uno de los genes mutantes, lo que resulta en un solo organismo que contiene ambos genes mutantes. Si la función genética defectuosa se restaura y el fenotipo deseado (comportamiento, apariencia u otras características observables) se produce en el organismo híbrido, entonces se dice que los genes complementan entre sí. Esto sugiere que los dos genes están involucrados en la misma vía bioquímica o proceso celular y son funcionalmente equivalentes.
Sin embargo, si no se produce el fenotipo deseado en el organismo híbrido, entonces se dice que los genes no complementan entre sí, lo que sugiere que están involucrados en diferentes vías bioquímicas o procesos celulares.
La prueba de complementación genética es una herramienta importante en la identificación y caracterización de genes mutantes asociados con enfermedades genéticas y puede ayudar a los científicos a comprender mejor los mecanismos moleculares subyacentes a las enfermedades.
En la biología molecular y genética, las proteínas represoras son tipos específicos de proteínas que reprimen o inhiben la transcripción de genes específicos en el ADN. Esto significa que impiden que la maquinaria celular lea e interprete la información genética contenida en los genes, lo que resulta en la no producción de las proteínas codificadas por esos genes.
Las proteínas represoras a menudo funcionan en conjunto con operones, que son grupos de genes relacionados que se transcriben juntos como una unidad. Cuando el organismo no necesita los productos de los genes del operón, las proteínas represoras se unirán al ADN en la región promotora del operón, evitando que el ARN polimerasa (la enzima que realiza la transcripción) se una y comience la transcripción.
Las proteínas represoras pueden ser activadas o desactivadas por diversos factores, como señales químicas u otras moléculas. Cuando se activan, cambian su forma y ya no pueden unirse al ADN, lo que permite que la transcripción tenga lugar. De esta manera, las proteínas represoras desempeñan un papel crucial en la regulación de la expresión génica y, por lo tanto, en la adaptabilidad y supervivencia de los organismos.
La mutagénesis insercional es un proceso mediante el cual se introduce intencionadamente un segmento de ADN extraño, como un transposón o un vector de clonación, en el genoma de un organismo. Esto puede causar una interrupción o alteración en la secuencia del ADN del gen, lo que lleva a una pérdida o modificación de la función del gen. La mutagénesis insercional se utiliza a menudo como una herramienta para estudiar la función de genes específicos y ha sido particularmente útil en el estudio de los genomas de organismos modelo, como las bacterias y los mamíferos. También se puede emplear en la investigación biomédica y biotecnológica para producir organismos con propiedades deseables o modificados genéticamente.
Es importante señalar que este proceso puede tener implicaciones no deseadas, ya que la inserción de ADN exógeno en el genoma puede perturbar la expresión y función normal de otros genes además del objetivo deseado, lo que podría conducir a efectos secundarios imprevistos. Por esta razón, es crucial llevar a cabo un análisis cuidadoso y exhaustivo antes y después de la mutagénesis insercional para minimizar los riesgos asociados con este procedimiento.
El análisis de secuencia de ADN se refiere al proceso de determinar la exacta ordenación de las bases nitrogenadas en una molécula de ADN. La secuencia de ADN es el código genético que contiene la información genética hereditaria y guía la síntesis de proteínas y la expresión génica.
El análisis de secuencia de ADN se realiza mediante técnicas de biología molecular, como la reacción en cadena de la polimerasa (PCR) y la secuenciación por Sanger o secuenciación de nueva generación. Estos métodos permiten leer la secuencia de nucleótidos que forman el ADN, normalmente representados como una serie de letras (A, C, G y T), que corresponden a las cuatro bases nitrogenadas del ADN: adenina, citosina, guanina y timina.
El análisis de secuencia de ADN se utiliza en diversas áreas de la investigación biomédica y clínica, como el diagnóstico genético, la identificación de mutaciones asociadas a enfermedades hereditarias o adquiridas, el estudio filogenético y evolutivo, la investigación forense y la biotecnología.
La beta-galactosidase es una enzima (un tipo de proteína que acelera reacciones químicas en el cuerpo) que ayuda a descomponer los azúcares específicos, llamados galactósidos. Se encuentra normalmente en las células de varios organismos vivos, incluyendo los seres humanos. En el cuerpo humano, la beta-galactosidase se produce en varias partes del cuerpo, como el intestino delgado, donde ayuda a descomponer la lactosa (un azúcar encontrado en la leche y los productos lácteos) en glucosa y galactosa, los cuales pueden ser absorbidos y utilizados por el cuerpo como fuente de energía.
La actividad de la beta-galactosidase también se utiliza a menudo como un marcador bioquímico en diversas pruebas de laboratorio. Por ejemplo, una prueba común llamada prueba de la bacteria "Escherichia coli" (E. coli) mide los niveles de beta-galactosidase para ayudar a identificar ciertas cepas de esta bacteria. Además, en la investigación biomédica, se utiliza a menudo una versión modificada de la beta-galactosidase de E. coli como un marcador de expresión génica, lo que permite a los científicos rastrear y medir la actividad de genes específicos en células vivas.
En resumen, la beta-galactosidase es una enzima importante que descompone los galactósidos y ayuda en la digestión de la lactosa. También se utiliza como un marcador bioquímico útil en diversas pruebas de laboratorio y la investigación biomédica.
*Salmonella typhimurium* es una especie de bacteria gramnegativa, flagelada y anaerobia facultativa perteneciente al género *Salmonella*. Es un patógeno importante que causa enfermedades gastrointestinales en humanos y animales de sangre caliente. La infección por *S. typhimurium* generalmente conduce a una forma leve de salmonelosis, que se manifiesta como diarrea, náuseas, vómitos y dolor abdominal. En casos raros, puede provocar una enfermedad invasiva sistémica grave, especialmente en personas con sistemas inmunes debilitados. La bacteria se transmite principalmente a través de alimentos o agua contaminados y puede afectar a una amplia gama de huéspedes, incluidos humanos, bovinos, porcinos, aves y reptiles.
En realidad, la terminología "cromosomas bacterianos" no es del todo correcta o está desactualizada. Los científicos y genetistas modernos prefieren el término "cromosoma bacteriano circular" o simplemente "genoma bacteriano", ya que las bacterias no poseen los cromosomas linearmente organizados como los eucariotas (organismos con células con núcleo verdadero, como los humanos).
El genoma bacteriano es un solo cromosoma circular, una molécula de ADN de cadena doble que forma un anillo continuo. Además del cromosoma bacteriano circular, las bacterias pueden tener uno o más plásmidos, que son pequeñas moléculas de ADN de cadena doble circulares que contienen genes adicionales y pueden transferirse entre bacterias mediante un proceso llamado conjugación.
Por lo tanto, una definición médica actualizada sería:
El cromosoma bacteriano circular es la única molécula de ADN de cadena doble en forma de anillo que contiene los genes y constituye el genoma de las bacterias. Las bacterias también pueden tener uno o más plásmidos, que son pequeñas moléculas de ADN circulares adicionales que contienen genes suplementarios.
La familia de multigenes, en términos médicos, se refiere a un grupo de genes relacionados que comparten una secuencia de nucleótidos similares y desempeñan funciones relacionadas en el cuerpo. Estos genes estrechamente vinculados se encuentran a menudo en los mismos cromosomas y pueden haber evolucionado a partir de un ancestro genético común a través de procesos como la duplicación génica o la conversión génica.
Las familias de multigenes desempeñan un papel importante en la diversificación funcional de los genes y en la adaptación genética. Pueden estar involucrados en una variedad de procesos biológicos, como el metabolismo, la respuesta inmunitaria y el desarrollo embrionario. La comprensión de las familias de multigenes puede ayudar a los científicos a entender mejor la regulación génica y la evolución molecular.
Los elementos transponibles de ADN, también conocidos como transposones o saltarines, son segmentos de ADN que tienen la capacidad de cambiar su posición dentro del genoma. Esto significa que pueden "saltar" de un lugar a otro en el ADN de un organismo.
Existen dos tipos principales de transposones: los de "clase 1" o retrotransposones, y los de "clase 2" o transposones DNA. Los retrotransposones utilizan un intermediario de ARN para moverse dentro del genoma, mientras que los transposones DNA lo hacen directamente a través de proteínas especializadas.
Estos elementos pueden representar una proporción significativa del genoma de algunos organismos, y su activación o inactivación puede desempeñar un papel importante en la evolución, la variabilidad genética y el desarrollo de enfermedades, como cánceres y trastornos genéticos.
El mapeo cromosómico es un proceso en genética molecular que se utiliza para determinar la ubicación y orden relativo de los genes y marcadores genéticos en un cromosoma. Esto se realiza mediante el análisis de las frecuencias de recombinación entre estos marcadores durante la meiosis, lo que permite a los genetistas dibujar un mapa de la posición relativa de estos genes y marcadores en un cromosoma.
El mapeo cromosómico se utiliza a menudo en la investigación genética para ayudar a identificar los genes que contribuyen a enfermedades hereditarias y otros rasgos complejos. También se puede utilizar en la medicina forense para ayudar a identificar individuos o determinar la relación entre diferentes individuos.
Existen diferentes tipos de mapeo cromosómico, incluyendo el mapeo físico y el mapeo genético. El mapeo físico implica la determinación de la distancia física entre los marcadores genéticos en un cromosoma, medida en pares de bases. Por otro lado, el mapeo genético implica la determinación del orden y distancia relativa de los genes y marcadores genéticos en términos del número de recombinaciones que ocurren entre ellos durante la meiosis.
En resumen, el mapeo cromosómico es una técnica importante en genética molecular que se utiliza para determinar la ubicación y orden relativo de los genes y marcadores genéticos en un cromosoma, lo que puede ayudar a identificar genes asociados con enfermedades hereditarias y otros rasgos complejos.
No hay una definición médica específica para "Sistemas de Lectura Abierta". El término generalmente se refiere a sistemas tecnológicos que permiten el acceso y uso compartido de libros electrónicos y otros materiales digitales con licencias abiertas. Estos sistemas pueden incluir bibliotecas digitales, repositorios de documentos y plataformas de publicación en línea que permiten a los usuarios leer, descargar, contribuir y modificar contenidos de forma gratuita o por una tarifa nominal.
En el contexto médico, los sistemas de lectura abierta pueden ser útiles para facilitar el acceso a investigaciones y publicaciones académicas en el campo de la medicina y la salud pública. Algunos editores médicos y organizaciones sin fines de lucro han adoptado modelos de licencias abiertas, como Creative Commons, para promover el intercambio y colaboración en investigaciones médicas y mejorar la atención médica global.
Sin embargo, es importante tener en cuenta que los sistemas de lectura abierta pueden variar en su alcance, funcionalidad y estándares de calidad. Antes de utilizar cualquier sistema de este tipo, es recomendable verificar sus políticas y prácticas relacionadas con la privacidad, la propiedad intelectual y los derechos de autor para garantizar el uso ético y legal del contenido.
En términos médicos o bioquímicos, un regulón se refiere a un conjunto de genes que son controlados o regulados por el mismo operador o factor de transcripción. Esto significa que estos genes comparten una secuencia específica en sus promotores a la que un factor de transcripción se une para regular su expresión. Cuando este factor de transcripción se une, puede activar o reprimir la transcripción de todos los genes en el regulón. Esta forma de control coordinado es común en muchos organismos, especialmente en bacterias.
El genoma bacteriano se refiere al conjunto completo de genes contenidos en el ADN de una bacteria. Estos genes codifican para todas las proteínas y moléculas funcionales necesarias para el crecimiento, desarrollo y supervivencia de la bacteria. El genoma bacteriano puede variar considerablemente entre diferentes especies de bacterias, con algunas especies que tienen genomas mucho más grandes y más complejos que otros.
El análisis del genoma bacteriano puede proporcionar información valiosa sobre la fisiología, evolución y patogénesis de las bacterias. Por ejemplo, el análisis del genoma de una bacteria patógena puede ayudar a identificar los genes que están involucrados en la enfermedad y el virulencia, lo que podría conducir al desarrollo de nuevas estrategias de tratamiento y prevención.
El genoma bacteriano típicamente varía en tamaño desde alrededor de 160.000 pares de bases en Mycoplasma genitalium a más de 14 millones de pares de bases en Sorangium cellulosum. El genoma de la mayoría de las bacterias se compone de un cromosoma circular único, aunque algunas especies también pueden tener uno o más plásmidos, que son pequeños círculos de ADN que contienen genes adicionales.
La represión enzimática es un proceso regulador en la bioquímica y genética que involucra la inhibición de la actividad enzimática. Ocurre cuando una molécula, a menudo otra proteína, se une a una enzima y previene su capacidad de unirse y catalizar su sustrato, reduciendo así la tasa de reacción. Esta forma de regulación es común en los sistemas vivos y ayuda a controlar las vías metabólicas, garantizando que se produzcan las cantidades adecuadas de moléculas en el momento adecuado.
Existen dos tipos principales de represión enzimática: la represión positiva y la represión negativa. En la represión positiva, la proteína represora se une al ADN de un operón (un grupo de genes que se transcriben juntos) en presencia de un inductor específico, evitando así que el operón se transcrija a ARNm. Por otro lado, en la represión negativa, la proteína represora normalmente se une al ADN y bloquea la transcripción del operón, pero en presencia de un inductor, la proteína represora se desprende del ADN, permitiendo que el operón se transcriba.
La represión enzimática es un mecanismo crucial para mantener el equilibrio y la homeostasis dentro de una célula. Ayuda a garantizar que las reacciones metabólicas importantes solo ocurran cuando sea necesario, evitando el desperdicio de energía y recursos. Además, permite a las células adaptarse rápidamente a los cambios en su entorno al modular la actividad enzimática en respuesta a diferentes señales y estímulos.
Lo siento para la confusión, pero en realidad no existe un término médico específico llamado "factor sigma". Es posible que desee verificar la ortografía o el contexto del término. Si se refiere a algún término relacionado con la biomedicina o la investigación, estaré encantado de ayudarle si proporciona más información al respecto.
Los genes son unidades fundamentales de herencia en los organismos vivos. Están compuestos por segmentos específicos del ADN (ácido desoxirribonucleico) que contienen información genética y dirigen la producción de proteínas, que a su vez desempeñan un papel crucial en el crecimiento, desarrollo y funcionamiento general de los organismos.
Cada gen tiene un lugar específico en un cromosoma y codifica una proteína particular o realiza alguna otra función importante en la regulación de las actividades celulares. Las variaciones en los genes pueden dar lugar a diferencias fenotípicas entre individuos, como el color de ojos, cabello o piel, y también pueden estar relacionadas con la predisposición a diversas enfermedades y trastornos.
La genética moderna ha permitido el estudio detallado de los genes y su función, lo que ha llevado al descubrimiento de nuevas terapias y tratamientos médicos, así como a una mejor comprensión de la diversidad y evolución de las especies.
La homología de secuencia de aminoácidos es un concepto en bioinformática y biología molecular que se refiere al grado de similitud entre las secuencias de aminoácidos de dos o más proteínas. Cuando dos o más secuencias de proteínas tienen una alta similitud, especialmente en regiones largas y continuas, es probable que desciendan evolutivamente de un ancestro común y, por lo tanto, se dice que son homólogos.
La homología de secuencia se utiliza a menudo como una prueba para inferir la función evolutiva y estructural compartida entre proteínas. Cuando las secuencias de dos proteínas son homólogas, es probable que también tengan estructuras tridimensionales similares y funciones biológicas relacionadas. La homología de secuencia se puede determinar mediante el uso de algoritmos informáticos que comparan las secuencias y calculan una puntuación de similitud.
Es importante destacar que la homología de secuencia no implica necesariamente una identidad funcional o estructural completa entre proteínas. Incluso entre proteínas altamente homólogas, las diferencias en la secuencia pueden dar lugar a diferencias en la función o estructura. Además, la homología de secuencia no es evidencia definitiva de una relación evolutiva directa, ya que las secuencias similares también pueden surgir por procesos no relacionados con la descendencia común, como la convergencia evolutiva o la transferencia horizontal de genes.
La fusión artificial génica no es un término médico establecido ni un procedimiento médico reconocido. Sin embargo, en el contexto de la biotecnología y la genética, la "fusión génica" generalmente se refiere a un proceso de ingeniería genética en el que los genes de dos organismos diferentes se combinan para producir una nueva secuencia genética con propiedades únicas. Esto no implica la fusión de dos organismos completos, sino simplemente la combinación de material genético de dos fuentes distintas.
El término "artificial" podría sugerir que este proceso se realiza deliberadamente en un laboratorio, a diferencia de las fusiones génicas naturales que pueden ocurrir en la naturaleza. Sin embargo, sigue siendo una práctica teórica y especulativa que no se ha llevado a cabo en humanos ni en ningún otro organismo vivo con fines médicos.
Por lo tanto, no hay una definición médica establecida para "fusión artificial génica".
La homología de secuencia de ácido nucleico es un término utilizado en genética y biología molecular para describir la similitud o semejanza entre dos o más secuencias de ADN o ARN. Esta similitud puede deberse a una relación evolutiva, donde las secuencias comparten un ancestro común y han heredado parte de su material genético.
La homología se mide generalmente como un porcentaje de nucleótidos coincidentes entre dos secuencias alineadas. Cuanto mayor sea el porcentaje de nucleótidos coincidentes, más altas serán las probabilidades de que las secuencias estén relacionadas evolutivamente.
La homología de secuencia es una herramienta importante en la investigación genética y biomédica. Se utiliza a menudo para identificar genes o regiones genómicas similares entre diferentes especies, lo que puede ayudar a inferir funciones genéticas conservadas. También se emplea en el análisis de variantes genéticas y mutaciones asociadas a enfermedades, ya que la comparación con secuencias de referencia puede ayudar a determinar si una variante es benigna o patogénica.
Sin embargo, es importante tener en cuenta que no todas las secuencias homólogas están relacionadas evolutivamente. Algunas secuencias pueden mostrar homología debido a procesos como la transferencia horizontal de genes o la duplicación genómica, por lo que otros métodos de análisis suelen ser necesarios para confirmar las relaciones evolutivas.
Las regiones terminadoras genéticas, también conocidas como regiones teloméricas, se refieren a las secuencias repetitivas de ADN que se encuentran en los extremos de los cromosomas. Estas regiones son cruciales para la estabilidad y protección de los cromosomas, ya que previenen su degradación y fusión con otros cromosomas.
Las regiones terminadoras genéticas están compuestas por miles de repeticiones de una secuencia simple de nucleótidos, generalmente de la forma TTAGGG en vertebrados. Estas secuencias se extienden hacia el extremo del cromosoma y pueden alcanzar longitudes de varios kilobases de pares de bases de ADN.
Además de su función protectora, las regiones terminadoras genéticas también desempeñan un papel importante en la regulación de la replicación del ADN y la estabilidad cromosómica. Durante la división celular, las enzimas conocidas como telomerasas agregar nuevas repeticiones de TTAGGG a los extremos de los cromosomas para compensar el acortamiento natural que ocurre durante la replicación del ADN. Sin embargo, con el paso del tiempo y el envejecimiento celular, las telomerasas no pueden mantener la longitud de las regiones terminadoras genéticas, lo que lleva a la senescencia celular y, finalmente, a la muerte celular programada.
La importancia de las regiones terminadoras genéticas ha sido destacada en el estudio del envejecimiento y diversas enfermedades relacionadas con la edad, como el cáncer. Los cambios en la longitud y la integridad de las regiones terminadoras genéticas se han asociado con una variedad de procesos patológicos y pueden utilizarse como biomarcadores para medir el daño del ADN y el estrés oxidativo.
Las Regiones Operadoras Genéticas (ROG) son segmentos específicos del DNA no codificante que contienen secuencias reguladoras importantes para la expresión génica. Estas regiones no codifican proteínas directamente, pero desempeñan un papel crucial en el control de cuándo, dónde y en qué cantidad se activa un gen en particular.
Las ROG pueden contener elementos enhancer, silencers, promoters y otros sitios de unión para factores de transcripción. Los enhancers son secuencias de DNA que aumentan la transcripción del gen, mientras que los silencers la disminuyen. Los promotores son regiones donde se une la ARN polimerasa II para iniciar la transcripción del gen.
Las ROG pueden estar ubicadas en distintos lugares en relación al gen que regulan, incluyendo dentro del intrón o el exón del gen, o en lugares distantes del gen en el mismo cromosoma. Para regular genes a distancia, las ROG interactúan con el gen a través de la formación de bucles de DNA, lo que permite que los factores de transcripción se unan y regulen la expresión génica.
Las mutaciones en las ROG pueden conducir a cambios en la expresión génica y estar asociadas con diversas enfermedades genéticas y complejos. Por lo tanto, el estudio de las ROG es importante para entender los mecanismos moleculares que subyacen a la regulación génica y su relación con la patogénesis de enfermedades.
La arabinosa es un monosacárido (un tipo simple de azúcar) que se encuentra en algunas moléculas de carbohidratos complejos, como las hemicelulosas y las pectinas, que se encuentran en la pared celular de las plantas. La arabinosa es un hexosa (un azúcar con 6 átomos de carbono) y es una forma de azúcar de pentosa (azúcares con 5 átomos de carbono) que se encuentra en la naturaleza.
En el cuerpo humano, la arabinosa puede desempeñar un papel como fuente de energía y también puede utilizarse en la síntesis de otros compuestos importantes. Sin embargo, no es un azúcar que se encuentre comúnmente en los alimentos o que el cuerpo utilice como fuente principal de energía.
En medicina, la arabinosa a veces se utiliza en forma de su sales sódicas (arabinosato de sodio) como un agente antimicrobiano y antiadherente para tratar infecciones del tracto urinario. Se cree que funciona al interferir con la capacidad de las bacterias para adherirse a las células de la vejiga y causar una infección. Sin embargo, se necesita más investigación para determinar su eficacia y seguridad en el tratamiento de las infecciones del tracto urinario.
"Pseudomonas putida" es una especie de bacterias gramnegativas, aerobias y móviles perteneciente al género Pseudomonas. Es un bacilo corto, generalmente de 0.5-1.0 por 1.5-3.0 micras, con un único flagelo polar. Se encuentra ampliamente distribuida en la naturaleza y se ha aislado de una gran variedad de hábitats, incluyendo suelos, aguas, plantas y animales.
Es conocida por su capacidad de degradar una amplia gama de compuestos orgánicos, lo que la convierte en un organismo importante en los ciclos biogeoquímicos naturales y en aplicaciones biotecnológicas. También es capaz de sobrevivir en condiciones adversas, como altas concentraciones de metales pesados o disolventes orgánicos, lo que la hace resistente a diversos agentes antibióticos y desinfectantes.
En humanos, "Pseudomonas putida" es un saprofito común y raramente causa enfermedades, excepto en individuos inmunodeprimidos o con sistemas defensivos debilitados. Sin embargo, se ha asociado con algunas infecciones nosocomiales, especialmente en pacientes hospitalizados con catéteres y otros dispositivos médicos invasivos.
La triptofanasa es una enzima que cataliza la reacción de descomposición del aminoácido triptófano en forma de β-indolilpiruvato y amoníaco. Esta reacción es la primera etapa en la ruta metabólica que conduce a la síntesis de niacina (vitamina B3) en el cuerpo humano. La actividad de la triptofanasa se utiliza como un indicador bioquímico del estado nutricional y de salud general, ya que su nivel disminuye durante el estrés, las infecciones y otras condiciones médicas graves. También desempeña un papel en la regulación del crecimiento y desarrollo, así como en la respuesta inmunitaria del organismo.
Los factores de transcripción son proteínas que regulan la transcripción genética, es decir, el proceso por el cual el ADN es transcrito en ARN. Estas proteínas se unen a secuencias específicas de ADN, llamadas sitios enhancer o silencer, cerca de los genes que van a ser activados o desactivados. La unión de los factores de transcripción a estos sitios puede aumentar (activadores) o disminuir (represores) la tasa de transcripción del gen adyacente.
Los factores de transcripción suelen estar compuestos por un dominio de unión al ADN y un dominio de activación o represión transcripcional. El dominio de unión al ADN reconoce y se une a la secuencia específica de ADN, mientras que el dominio de activación o represión interactúa con otras proteínas para regular la transcripción.
La regulación de la expresión génica por los factores de transcripción es un mecanismo fundamental en el control del desarrollo y la homeostasis de los organismos, y está involucrada en muchos procesos celulares, como la diferenciación celular, el crecimiento celular, la respuesta al estrés y la apoptosis.
La "eliminación de gen" no es un término médico ampliamente reconocido o utilizado en la literatura médica. Sin embargo, dado que en el contexto proporcionado puede referirse al proceso de eliminar o quitar un gen específico durante la investigación genética o la edición de genes, aquí está una definición relacionada:
La "eliminación de gen" o "gen knockout" es un método de investigación genética que involucra la eliminación intencional de un gen específico de un organismo, con el objetivo de determinar su función y el papel en los procesos fisiológicos. Esto se logra mediante técnicas de ingeniería genética, como la inserción de secuencias de ADN que interrumpen o reemplazan el gen diana, lo que resulta en la producción de una proteína no funcional o ausente. Los organismos con genes knockout se utilizan comúnmente en modelos animales para estudiar enfermedades y desarrollar terapias.
Tenga en cuenta que este proceso también puede denominarse "gen knockout", "knocking out a gene" o "eliminación génica".
Las proteínas de unión al ADN (DUA o DNA-binding proteins en inglés) son un tipo de proteínas que se unen específicamente a secuencias de nucleótidos particulares en el ácido desoxirribonucleico (ADN). Estas proteínas desempeñan funciones cruciales en la regulación y control de los procesos celulares, como la transcripción génica, la replicación del ADN, la reparación del ADN y el empaquetamiento del ADN en el núcleo celular.
Las DUA pueden unirse al ADN mediante interacciones no covalentes débiles, como enlaces de hidrógeno, interacciones electrostáticas y fuerzas de van der Waals. La especificidad de la unión entre las proteínas de unión al ADN y el ADN se determina principalmente por los aminoácidos básicos (como lisina y arginina) e hidrofóbicos (como fenilalanina, triptófano y tirosina) en la región de unión al ADN de las proteínas. Estos aminoácidos interactúan con los grupos fosfato negativamente cargados del esqueleto de azúcar-fosfato del ADN y las bases nitrogenadas, respectivamente.
Las proteínas de unión al ADN se clasifican en diferentes categorías según su estructura y función. Algunos ejemplos importantes de proteínas de unión al ADN incluyen los factores de transcripción, las nucleasas, las ligasas, las helicasas y las polimerasas. El mal funcionamiento o la alteración en la expresión de estas proteínas pueden dar lugar a diversas enfermedades genéticas y cánceres.
El término "orden génico" se refiere al orden específico en el que los genes están dispuestos en un cromosoma. Cada especie tiene un orden génico característico y único en sus cromosomas, y este patrón de organización es crucial para la expresión adecuada de los genes y la funcionalidad normal del genoma.
Las mutaciones que alteran el orden génico, como las inversiones o translocaciones cromosómicas, pueden desencadenar cambios en la expresión génica y dar lugar a diversas anomalías genéticas y desarrollo anormal. Por lo tanto, el orden génico es un aspecto fundamental de la organización del genoma y tiene importantes implicaciones en la biología y patología celulares.
En resumen, el 'orden génico' se refiere al orden lineal específico de los genes en un cromosoma, que es crucial para la expresión adecuada de los genes y la funcionalidad normal del genoma. Las alteraciones en el orden génico pueden desencadenar diversas anomalías genéticas y desarrollo anormal.
La virulencia, en el contexto médico y biológico, se refiere a la capacidad inherente de un microorganismo (como bacterias, virus u hongos) para causar daño o enfermedad en su huésped. Cuando un agente infeccioso es más virulento, significa que tiene una mayor probabilidad de provocar síntomas graves o letales en el huésped.
La virulencia está determinada por diversos factores, como la producción de toxinas y enzimas que dañan tejidos, la capacidad de evadir o suprimir las respuestas inmunitarias del huésped, y la eficiencia con la que el microorganismo se adhiere a las células y superficies del cuerpo.
La virulencia puede variar entre diferentes cepas de un mismo microorganismo, lo que resulta en diferentes grados de patogenicidad o capacidad de causar enfermedad. Por ejemplo, algunas cepas de Escherichia coli son inofensivas y forman parte de la flora intestinal normal, mientras que otras cepas altamente virulentas pueden causar graves infecciones gastrointestinales e incluso falla renal.
Es importante tener en cuenta que la virulencia no es un rasgo fijo y puede verse afectada por diversos factores, como las condiciones ambientales, el estado del sistema inmunitario del huésped y la dosis de exposición al microorganismo.
El triptófano es un aminoácido esencial, lo que significa que el cuerpo no puede producirlo por sí solo y debe obtenerse a través de la dieta. Es uno de los 20 aminoácidos que forman las proteínas.
El triptófano juega un papel importante en la producción de serotonina, una hormona que ayuda a regular el estado de ánimo y el sueño. También desempeña un papel en la producción de vitamina B3 (niacina).
Los alimentos ricos en triptófano incluyen carne, pollo, pescado, huevos, productos lácteos, nueces y semillas, y algunas legumbres como las habas y los garbanzos.
En el contexto médico, se puede recetar triptófano suplementario para tratar ciertas afecciones, como la deficiencia de triptófano o en combinación con otros aminoácidos para tratar trastornos del sueño y depresión. Sin embargo, el uso de suplementos de triptófano es objeto de debate y no se recomienda generalmente como terapia inicial para estas afecciones. Además, los suplementos de triptófano pueden interactuar con ciertos medicamentos y tener efectos secundarios, por lo que siempre se debe consultar a un médico antes de comenzar a tomar cualquier suplemento.
La Proteína Reguladora de Respuesta a la Leucina (LRR, por sus siglas en inglés) es un tipo de proteína que se ha identificado como un regulador clave en los procesos anabólicos relacionados con la síntesis de proteínas y el crecimiento muscular. La LRR desempeña su función mediante la activación de la vía mTOR (mammalian target of rapamycin), un importante camino metabólico que regula el crecimiento celular y la homeostasis energética.
La leucina, un aminoácido esencial, desempeña un papel fundamental en la activación de la LRR. Cuando los niveles de leucina en el cuerpo aumentan, especialmente después de una comida rica en proteínas o un entrenamiento de resistencia, la LRR se activa y promueve la síntesis de proteínas musculares al interactuar con mTOR. Esta interacción activa los complejos mTORC1 y mTORC2, que a su vez desencadenan una serie de eventos moleculares que conducen al crecimiento y la reparación del tejido muscular.
La proteína reguladora de respuesta a la leucina también está involucrada en otros procesos celulares, como la autofagia, la transcripción génica y la señalización intracelular. Los trastornos en la vía mTOR y la disfunción de la LRR se han relacionado con diversas afecciones clínicas, como el cáncer, la diabetes y las enfermedades neurodegenerativas. Por lo tanto, comprender el papel y el mecanismo de acción de la proteína reguladora de respuesta a la leucina puede tener importantes implicaciones terapéuticas para una variedad de enfermedades.
La definición médica de "ARN polimerasas dirigidas por ADN" se refiere a un tipo de enzimas que sintetizan ARN (ácido ribonucleico) utilizando una molécula de ADN (ácido desoxirribonucleico) como plantilla o molde.
Las ARN polimerasas dirigidas por ADN son esenciales para la transcripción, el proceso mediante el cual el código genético contenido en el ADN se copia en forma de ARN mensajero (ARNm), que luego se utiliza como plantilla para la síntesis de proteínas.
Existen varios tipos de ARN polimerasas dirigidas por ADN, cada una con funciones específicas y reguladas de manera diferente en la célula. Algunas de estas enzimas participan en la transcripción de genes que codifican proteínas, mientras que otras sintetizan ARN no codificantes, como los ARN ribosómicos (ARNr) y los ARN de transferencia (ARNt), que desempeñan funciones estructurales y catalíticas en la síntesis de proteínas.
Las ARN polimerasas dirigidas por ADN son objetivos importantes para el desarrollo de fármacos antivirales, ya que muchos virus dependen de las ARN polimerasas virales para replicar su genoma y producir proteínas. Los inhibidores de la ARN polimerasa dirigidos por ADN pueden interferir con la replicación del virus y reducir su capacidad de infectar células huésped.
La conformación del ácido nucleico se refiere a la estructura tridimensional que adopta el ácido nucleico, ya sea ADN (ácido desoxirribonucleico) o ARN (ácido ribonucleico), una vez que se ha producido su doble hélice. La conformación de estas moléculas puede variar dependiendo de factores como la secuencia de nucleótidos, el entorno químico y físico, y las interacciones con otras moléculas.
Existen dos conformaciones principales del ADN: la forma B y la forma A. La forma B es la más común en condiciones fisiológicas y se caracteriza por una hélice dextrógira con un paso de rotación de 34,3 Å (ångstroms) y un diámetro de 20 Å. Los nucleótidos se disponen en forma de pirámide con el azúcar en la base y las bases apiladas en la cima. La forma A, por otro lado, tiene una hélice más corta y ancha, con un paso de rotación de 27,5 Å y un diámetro de 23 Å. Esta conformación se presenta en condiciones deshidratadas o con altas concentraciones de sales.
El ARN también puede adoptar diferentes conformaciones, dependiendo del tipo de molécula y de las condiciones ambientales. El ARN mensajero (ARNm), por ejemplo, tiene una conformación similar a la forma A del ADN, mientras que el ARN de transferencia (ARNt) adopta una estructura más compacta y globular.
La conformación del ácido nucleico es importante para su reconocimiento y unión con otras moléculas, como las proteínas, y desempeña un papel crucial en la regulación de la expresión génica y la replicación del ADN.
La alineación de secuencias es un proceso utilizado en bioinformática y genética para comparar dos o más secuencias de ADN, ARN o proteínas. El objetivo es identificar regiones similares o conservadas entre las secuencias, lo que puede indicar una relación evolutiva o una función biológica compartida.
La alineación se realiza mediante el uso de algoritmos informáticos que buscan coincidencias y similitudes en las secuencias, teniendo en cuenta factores como la sustitución de un aminoácido o nucleótido por otro (puntos de mutación), la inserción o eliminación de uno o más aminoácidos o nucleótidos (eventos de inserción/deleción o indels) y la brecha o espacio entre las secuencias alineadas.
Existen diferentes tipos de alineamientos, como los globales que consideran toda la longitud de las secuencias y los locales que solo consideran regiones específicas con similitudes significativas. La representación gráfica de una alineación se realiza mediante el uso de caracteres especiales que indican coincidencias, sustituciones o brechas entre las secuencias comparadas.
La alineación de secuencias es una herramienta fundamental en la investigación genética y biomédica, ya que permite identificar relaciones evolutivas, determinar la función de genes y proteínas, diagnosticar enfermedades genéticas y desarrollar nuevas terapias y fármacos.
Las enzimas de restricción del ADN son endonucleasas bacterianas que reconocen secuencias específicas de nucleótidos en el ADN doble cadena y los cortan en posiciones particulares, generando fragmentos de ADN con extremos compatibles para unirse a otros fragmentos de ADN mediante reacciones de ligación.
Estas enzimas se utilizan comúnmente en biología molecular como herramientas para el corte y manipulación del ADN, como por ejemplo en la clonación molecular y el análisis de restricción de fragmentos de ADN (RFLP). Las enzimas de restricción se clasifican según su especificidad de reconocimiento de secuencias de nucleótidos y los patrones de corte que generan. Algunas enzimas de restricción cortan el ADN dejando extremos cohesivos o compatibles, mientras que otras dejan extremos romos o sin complementariedad.
El nombre "enzimas de restricción" se deriva del mecanismo por el cual las bacterias utilizan estas enzimas para protegerse contra virus (bacteriófagos). Las bacterias modifican su propio ADN marcándolo con metilación, lo que previene el corte de sus propias enzimas de restricción. Sin embargo, los virus invasores no están marcados y por lo tanto son vulnerables al corte y destrucción por las enzimas de restricción bacterianas.
La anaerobiosis es un estado en el que un organismo o un tipo particular de células puede vivir y crecer en ausencia de oxígeno. Los organismos que pueden sobrevivir en tales condiciones se denominan anaerobios. Hay dos tipos principales de anaerobiosis: la obligada y la facultativa.
La anaerobiosis obligada ocurre cuando un organismo solo puede crecer y desarrollarse en ausencia total de oxígeno. Si se expone a niveles incluso bajos de oxígeno, este tipo de organismos anaerobios pueden sufrir daños graves o incluso morir.
Por otro lado, la anaerobiosis facultativa se produce cuando un organismo puede crecer y desarrollarse tanto en presencia como en ausencia de oxígeno. Estos organismos prefieren vivir en condiciones con oxígeno, pero pueden adaptarse y sobrevivir sin él.
En el contexto médico, la anaerobiosis puede ser relevante en diversas situaciones, como por ejemplo en infecciones causadas por bacterias anaerobias que pueden ocurrir en tejidos con bajos niveles de oxígeno, como las heridas infectadas o los abscesos. Estas bacterias anaerobias pueden producir toxinas y otros factores patógenos que contribuyen a la gravedad de la infección. El tratamiento de estas infecciones requiere el uso de antibióticos específicos que sean eficaces contra las bacterias anaerobias.
'Escherichia coli K12' es una cepa específica del bacterio gram-negativo común, Escherichia coli (E. coli). Esta cepa se utiliza ampliamente en la investigación científica y médica como organismo modelo. Es particularmente conocida por su genoma bien caracterizado y sus propiedades seguras y estables. A diferencia de algunas otras cepas de E. coli, K12 no es un patógeno intestinal humano y generalmente se considera no patogénica. Sin embargo, puede causar infecciones oportunistas en individuos con sistemas inmunológicos debilitados.
La cepa K12 tiene una serie de propiedades útiles para la investigación, incluyendo su capacidad para crecer en un amplio rango de condiciones y su susceptibilidad a una variedad de técnicas genéticas. Fue aislada por primera vez en 1922 por E.G. Hasse y W.E. Draper en la Universidad de Stanford, y desde entonces se ha utilizado en miles de estudios científicos. El genoma de E. coli K12 fue secuenciado por primera vez en 1997, lo que representó un hito importante en la historia de la genómica microbiana.
La lactosa es un tipo de azúcar complejo (disacárido) que se encuentra naturalmente en la leche y los productos lácteos de los mamíferos. Está formada por dos moléculas más pequeñas de azúcares simples: glucosa y galactosa.
Para que el cuerpo humano pueda absorber y utilizar la lactosa, necesita una enzima llamada lactasa, que se produce en el intestino delgado. La lactasa descompone la lactosa en glucosa y galactosa, las cuales luego pueden ser absorbidas a través de la pared intestinal hacia la sangre.
Algunas personas carecen o tienen deficiencia de la enzima lactasa, lo que provoca una afección conocida como intolerancia a la lactosa. Cuando estas personas consumen productos lácteos, la lactosa no descompuesta puede llegar al colon, donde es fermentada por las bacterias intestinales, produciendo gases, hinchazón, calambres abdominales y diarrea.
En resumen, la lactosa es un tipo de azúcar presente en los productos lácteos que requiere de la enzima lactasa para su descomposición y absorción adecuada en el intestino delgado. La deficiencia o falta de esta enzima puede dar lugar a intolerancia a la lactosa, una condición común que provoca diversos síntomas digestivos desagradables.
 Operón - Wikipedia
Operón - Wikipedia
 operon-laboratorios-1 | MIT Comunicación Estratégica
operon-laboratorios-1 | MIT Comunicación Estratégica
ARN no codificante - Wikipedia, la enciclopedia libre
 Lewin. Genes de Jocelyn E. Krebs | Editorial Médica Panamericana
Lewin. Genes de Jocelyn E. Krebs | Editorial Médica Panamericana
 Linea del tiempo e historia de la genetica | Monografías Plus
Linea del tiempo e historia de la genetica | Monografías Plus
 Quirurgicas - Equipo Médico Nuevo, Usado y Reacondicionado
Quirurgicas - Equipo Médico Nuevo, Usado y Reacondicionado
 Braden o Per n - El Estadista
Braden o Per n - El Estadista VIDEO: Lectores de test rápidos y pruebas de anticuerpos, en el futuro del diagnóstico desde Zaragoza
VIDEO: Lectores de test rápidos y pruebas de anticuerpos, en el futuro del diagnóstico desde Zaragoza
 DeCS 2014 - versión 16 de diciembre de 2014
DeCS 2014 - versión 16 de diciembre de 2014
 Estamos, de los bailarines, hasta los cataplines. - Mundoclasico.com
Estamos, de los bailarines, hasta los cataplines. - Mundoclasico.com
 DRE SLS 9000 - MedicTechnology
DRE SLS 9000 - MedicTechnology
Universiteti i Andeve (Venezuela) - Wikipedia
 Subjekti "Banka Credins Kosovë" merr miratimin paraprak të licencës | Banka Qendrore e Republikës së Kosovës
Subjekti "Banka Credins Kosovë" merr miratimin paraprak të licencës | Banka Qendrore e Republikës së Kosovës
DeCS 2016 - versión 28 de julio de 2016
DeCS 2017 - versión 04 de julio de 2017
DeCS 2014 - versión 16 de diciembre de 2014
DeCS 2014 - versión 16 de diciembre de 2014
DeCS 2015 - versión 22 de diciembre de 2015
Lactosa - Wikipedia, la enciclopedia libre
 Búsqueda | BVS CLAP/SMR-OPS/OMS
Búsqueda | BVS CLAP/SMR-OPS/OMS
 Fundación Instituto Roche - Glosario de genética
Fundación Instituto Roche - Glosario de genética
 Salud archivos - Go Aragón
Salud archivos - Go Aragón
 Exportaciones de Selcansa sa | CESCE
Exportaciones de Selcansa sa | CESCE
 congelador - Centro Integral de Servicio para Laboratorio
congelador - Centro Integral de Servicio para Laboratorio Núcleo celular - Naturaleza molecular del Gen y el Genoma (7) - Todo CBC
Núcleo celular - Naturaleza molecular del Gen y el Genoma (7) - Todo CBC
 UTILIZACIÓN DE LA DGGE PARA LA CARACTERIZACIÓN DE LA ... · Utilización de la DGGE para la caracterización de la microbiota...
UTILIZACIÓN DE LA DGGE PARA LA CARACTERIZACIÓN DE LA ... · Utilización de la DGGE para la caracterización de la microbiota...
Fundación Instituto Roche - Glosario de genética
 Sensibilidad y especificidad del método inmunocromatográfico utilizado para el diagnóstico de rotavirus
Sensibilidad y especificidad del método inmunocromatográfico utilizado para el diagnóstico de rotavirus
 ARN mensajero (ARNm): los mensajeros del genoma
ARN mensajero (ARNm): los mensajeros del genoma
 Instituto Nacional de Investigaciones Forestales, Agrícolas y Pecuarias | Gobierno | gob.mx
Instituto Nacional de Investigaciones Forestales, Agrícolas y Pecuarias | Gobierno | gob.mx
Genes21
- Un operón se define como una unidad genética funcional formada por un grupo complejo de genes capaces de ejercer una regulación de su propia expresión por medio de los sustratos con los que interactúan las proteínas codificadas por sus genes. (wikipedia.org)
- Este complejo está formado por genes estructurales que codifican para la síntesis de proteínas (generalmente enzimas), que participan en vías metabólicas cuya expresión generalmente está regulada por otros 3 factores de control, llamados: Factor promotor: zona que controla el inicio de la transcripción del operón, ya que la ARN polimerasa tiene afinidad por ella. (wikipedia.org)
- Sin embargo, es común referirse a los "genes" del operón para hacer referencia a las regiones que, una vez transcritas, codificarán proteínas independientes. (wikipedia.org)
- Gen regulador: alguno de los genes del operón pueden codificar factores de transcripción que se unan al operador, regulando así la propia expresión del operón. (wikipedia.org)
- Los principales elementos que constituyen un operón son los siguientes: Los genes estructurales: Llevan información para traducir proteínas (polipéptidos). (wikipedia.org)
- El gen regulador está cerca de los genes estructurales del operón pero no está inmediatamente al lado. (wikipedia.org)
- Inductor: sustrato o compuesto cuya presencia/ausencia induce la expresión del resto de los genes que conforman el operón. (wikipedia.org)
- Operón inducible es el que en condiciones normales no se expresa, se activa en respuesta a un agente inductor que funciona como Activador, en el momento que el inductor se une al operador, se activa el promotor y comienza la transcripción de los genes estructurales. (wikipedia.org)
- El genoma es el conjunto de la información genética de un organismo, es decir, el conjunto de genes, entendiendo como tales sólo a los fragmentos codificantes del ADN, y no los elementos reguladores o espaciadores. (rincondelvago.com)
- Es muy fácil determinar la cantidad e, incluso, la secuencia del ADN, pero detectar en él los genes no es tarea fácil, y mucho más difícil es el estudio de la interacción génica. (rincondelvago.com)
- Genes solapados: Un mismo fragmento de ADN contiene información correspondiente a dos o más genes, es decir, comparten secuencia en determinados sitios. (rincondelvago.com)
- El operón produce la síntesis de un ARNm policistrónico, en el que se encuentran varios genes concatenados, pero cada uno con su comienzo y su final, con lo que las proteínas se sintetizan independientemente. (rincondelvago.com)
- Este sistema de almacenamiento de la información requiere la existencia de genes interrumpidos, es decir, con exones e intrones, y está presente en eucariotas, aumentando la complejidad con la del organismo. (rincondelvago.com)
- Pasando a considerar genomas reales de seres vivos, se observa que sólo los virus almacenan los genes en cualquier forma de ácido nucleico, es decir, tanto ADN como ARN y de cadena doble o sencilla. (rincondelvago.com)
- Como ya se ha apuntado, la cuantificación de ácidos nucleicos es muy fácil, comparado con la detección de genes. (rincondelvago.com)
- En 1944, Oswald T. Avery demostró en el Instituto (hoy Universidad) Rockefeller que el ácido desoxirribonucleico (adn) es la sustancia de la cual están hechos los genes. (edu.mx)
- La caracterización de nuestro mutante ery nos llevó a caracterizar un operón que contiene genes para el catabolismo del eritritol dentro deun agrupamiento mayor que contiene genes para transporte del eritritol y otros genes del metabolismo de carbohidratos , todos ellos inducibles por la presencia de eritritol en el medio de cultivo. (micromolecular.es)
- Sorprendentemente encontramos que la cepa vacunal S19, sensible a eritritol, ha sufrido una delección que afecta a dos genes esenciales del operón. (micromolecular.es)
- Otra aplicación de este trabajo contempla el desarrollo de vacunas para la brucelosis bovina construidas introduciendo de forma controlada mutaciones en los genes del eritritol y el operon de la ureasa, otro de los factores de virulencia que hemos caracterizado en Brucella . (micromolecular.es)
- Sus aportaciones han sido: desvelar cómo se regula la expresión de los genes en bacterias, la elaboración del modelo del operón y el estudio del desarrollo animal con el embrión de ratón como modelo. (uv.es)
- Para ello, se estudiaron los cambios inducidos por el pesticida en los niveles de RNA mensajero de genes responsables de la síntesis de la microcistina, operon mcy, genes reguladores de este operon y niveles de toxina producidos. (unizar.es)
Modelo2
- El modelo clásico de este tipo de operón es el operon lactosa. (wikipedia.org)
- Un modelo fiscal que no agobie el espíritu emprendedor por este proyecto compartido que es Aragón", ha sostenido. (directivosadea.com)
Escherichia1
- El primer operón descrito fue el operón de la lactosa en Escherichia coli por F. Jacob, D. Perrin, C. Sánchez y J. Monod, publicado en la revista "Comptes rendus hebdomadaires des séances de l'Académie des sciences" en 1960. (wikipedia.org)
Operones1
- Otros ejemplos de operones inducibles son aquellos que codifican para enzimas que participan en el metabolismo de sustratos como operon maltosa, arabinosa, etc. (wikipedia.org)
Jacob2
- François Jacob nos cuenta la historia del nacimiento del operón en el libro The Birth of the Operon, publicado en Science (332: 767, 13 de mayo de 2011). (mgyf.org)
- François Jacob, Premio Nobel de Fisiología o Medicina en 1965 y doctor Honoris Causa por la Universitat de València desde 1993, es uno de los biólogos más distinguidos del siglo XX. (uv.es)
Explica1
- Una de las peculiaridades de este género bacteriano, y que explica en gran manera su éxito, es que carece de factores de virulencia clásicos, y más bien ha desarrollado una estrategia furtiva, de modificación de sus patrones moleculares asociados a patógenos para evitar ser reconocido en primera instancia por el sistema inmune innato, y lograr éxito en la infección. (micromolecular.es)
Bacterias4
- Es el sistema de organización encontrado en bacterias, mitocondrias y cloroplastos. (rincondelvago.com)
- Es un informe confidencial aunque se corresponden con algunas de las bacterias no patógenas que cito en esta entrada. (fitopasion.com)
- La buena noticia es que la inmensa mayoría de bacterias bioluminiscentes no son dañinas ni tóxicas: tan sólo Vibrio vulnificus y V. cholerae se consideran patógenas (y la primera es la única que puede vivir en el mar). (fitopasion.com)
- La brucelosis es una zoonosis producida por diversas bacterias del género Brucella , como B. melitensis , B. abortus y B. suis . (micromolecular.es)
ARNm1
- más correcto sería decir que el operón es un único gen que codifica un ARNm policistrónico (es decir, con muchos codones de inicio y término, con lo que a la hora de traducirse dará lugar a varias proteínas independientes). (wikipedia.org)
Tipo1
- Concretamente uno de los sistemas más correlacionados con la virulencia de Brucella ha resultado ser un sistema de secreción de tipo IV, que se conoce como el operón vir de Brucella. (micromolecular.es)