Dna Restriction Enzymes
Polymorphisme Fragment Adn
Type Ii Site-Specific Deoxyribonuclease
Type I Site-Specific Deoxyribonuclease
Cartographie De Restriction
Séquence Nucléotidique
Deoxyribonuclease Ecori
Adn
Hybridation Acide Nucléique
Enzymes Restriction-Modification Adn
Plasmides
Electrophoresis, Agar Gel
Deoxyribonuclease Bamhi
Deoxyribonuclease Hindiii
Réaction Polymérisation En Chaîne
Adn Ribosomique
Données Séquence Moléculaire
Restriction Calorique
Coupure De L'Adn
Site-Specific Dna-Methyltransferase (Adenine-Specific)
Clonage Moléculaire
Empreinte Génétique
Gènes
Southern-Blot
Escherichia Coli
Techniques Typage Bactérien
Adn Recombinant
Spécificité Espèce
Cartographie Chromosomique
Electrophoresis, Gel, Pulsed-Field
Olivomycine
Polymorphisme Génétique
Arn Ribosomique 16S
Desoxyribonuclease Hpaii
Détermination Séquence Adn
Infections Humaines
Adn Circulaire
Génotype
Type Iii Site-Specific Deoxyribonuclease
Arn Ribosomique
Mutation
Sérotypie
Sondes Adn
Les enzymes de restriction de l'ADN sont des endonucléases qui coupent l'ADN (acide désoxyribonucléique) à des sites spécifiques déterminés par la séquence nucléotidique. Elles sont largement utilisées dans les techniques de biologie moléculaire, telles que le clonage et l'analyse de l'ADN.
Les enzymes de restriction sont produites principalement par des bactéries et des archées comme mécanisme de défense contre les virus (bactériophages). Elles coupent l'ADN viral, empêchant ainsi la réplication du virus dans la cellule hôte.
Chaque enzyme de restriction reconnaît une séquence nucléotidique spécifique dans l'ADN, appelée site de restriction. La plupart des enzymes de restriction coupent les deux brins de l'ADN au milieu du site de restriction, générant des extrémités cohésives ou collantes. Certaines enzymes de restriction coupent chaque brin à des distances différentes du site de restriction, produisant des extrémités décalées ou émoussées.
Les enzymes de restriction sont classées en fonction de la manière dont elles coupent l'ADN. Les deux principaux types sont les endonucléases de type II et les endonucléases de type I et III. Les endonucléases de type II sont les plus couramment utilisées dans les applications de recherche en biologie moléculaire en raison de leur spécificité élevée pour des séquences d'ADN particulières et de leurs propriétés d'endonucléase.
Les enzymes de restriction sont un outil essentiel dans les techniques de génie génétique, notamment le clonage moléculaire, l'analyse des gènes et la cartographie de l'ADN. Ils permettent aux scientifiques de manipuler et d'étudier l'ADN avec une grande précision et flexibilité.
Le polymorphisme de fragment d'ADN (VNTR, Variable Number of Tandem Repeats) est un type de variabilité génétique qui se produit dans les régions non codantes de l'ADN. Il est caractérisé par la présence de séquences répétées d'unités courtes (de 2 à 6 paires de bases) qui sont répétées en tandem et dont le nombre varie considérablement entre les individus.
Ces régions VNTR peuvent être trouvées dans tout le génome, mais elles sont particulièrement concentrées dans les régions non codantes entre les gènes. La longueur totale de ces régions répétées peut varier considérablement d'un individu à l'autre, ce qui entraîne des variations de taille des fragments d'ADN qui peuvent être détectés par des techniques de laboratoire telles que la Southern blotting ou la PCR.
Les VNTR sont considérés comme des marqueurs génétiques utiles dans l'identification individuelle et la médecine forensique, car les schémas de répétition varient considérablement entre les individus, même au sein d'une population donnée. Cependant, ils peuvent également être utilisés pour étudier la diversité génétique et l'évolution des populations, ainsi que dans la recherche médicale pour identifier les facteurs de susceptibilité à certaines maladies.
La « Type II Site-Specific Deoxyribonuclease » est une enzyme de restriction qui coupe l'ADN (acide désoxyribonucleique) de manière spécifique à un site particulier sur la molécule d'ADN. Cette enzyme est également appelée « endonucléase de restriction » et elle joue un rôle important dans les processus biologiques tels que la réparation de l'ADN, la recombinaison génétique et la défense contre les infections virales.
Les endonucléases de restriction de type II sont capables de reconnaître des séquences d'ADN spécifiques, généralement palindromiques (identiques à l'envers), et coupent les deux brins de la molécule d'ADN à des distances définies de cette séquence. Les endonucléases de restriction de type II sont classées en fonction de leur spécificité de reconnaissance du site, qui peut varier considérablement entre différentes enzymes.
La précision et la spécificité des endonucléases de restriction de type II les rendent utiles dans les applications de biologie moléculaire, telles que l'ingénierie génétique et l'analyse de l'ADN. Elles sont souvent utilisées pour couper l'ADN en fragments spécifiques, qui peuvent ensuite être purifiés et analysés pour étudier la structure et la fonction des gènes.
Cependant, il est important de noter que les endonucléases de restriction peuvent également présenter un risque pour la sécurité biologique, car elles peuvent être utilisées pour manipuler des agents pathogènes d'une manière qui accroît leur virulence ou leur résistance aux traitements. Par conséquent, leur utilisation est strictement réglementée dans de nombreux pays.
La « Type I Site-Specific Deoxyribonuclease » est une enzyme de restriction spécifique à un site qui coupe l'ADN (acide désoxyribonucléique) de manière asymétrique. Elle reconnaît et clive les séquences d'ADN spécifiques, créant ainsi des extrémités cohésives ou collantes. Les enzymes de restriction de type I sont généralement trouvées dans les bactéries et sont souvent associées à des systèmes de restriction-modification qui protègent la bactérie contre l'infection par des phages (virus bactériens).
Les enzymes de restriction de type I sont complexes et se composent de plusieurs sous-unités protéiques différentes, chacune ayant une fonction spécifique. Elles nécessitent généralement l'ajout d'ATP (adénosine triphosphate) pour être actives et cliver l'ADN. Les enzymes de restriction de type I sont également capables de se déplacer le long de l'ADN après avoir initié la coupure, ce qui leur permet de rechercher d'autres sites de reconnaissance et de clivage sur le même brin d'ADN.
Les enzymes de restriction de type I sont souvent désignées par un code alphabétique qui indique leur source bactérienne et leurs propriétés spécifiques. Par exemple, l'enzyme de restriction EcoRI est une enzyme de restriction de type II qui reconnaît et clive la séquence 5'-GAATTC-3' dans l'ADN. En revanche, les enzymes de restriction de type I ne sont pas aussi largement utilisées en recherche génétique et en biotechnologie que les enzymes de restriction de type II, car elles sont plus complexes et moins bien caractérisées.
L'ADN bactérien fait référence à l'acide désoxyribonucléique présent dans les bactéries. Il s'agit du matériel génétique héréditaire des bactéries, qui contient toutes les informations nécessaires à leur croissance, leur développement et leur fonctionnement.
Contrairement à l'ADN des cellules humaines, qui est organisé en chromosomes situés dans le noyau de la cellule, l'ADN bactérien se présente sous forme d'une unique molécule circulaire située dans le cytoplasme de la cellule. Cette molécule d'ADN bactérien est également appelée chromosome bactérien.
L'ADN bactérien peut contenir des gènes codant pour des protéines, des ARN non codants et des éléments régulateurs qui contrôlent l'expression des gènes. Les bactéries peuvent également posséder de l'ADN extrachromosomique sous forme de plasmides, qui sont des petites molécules d'ADN circulaires contenant un ou plusieurs gènes.
L'étude de l'ADN bactérien est importante pour comprendre la physiologie et le métabolisme des bactéries, ainsi que pour développer des stratégies de lutte contre les infections bactériennes. Elle permet également d'identifier des marqueurs spécifiques qui peuvent être utilisés pour caractériser et classer différentes espèces bactériennes.
La « cartographie des restrictions » est une technique utilisée en génétique et en biologie moléculaire pour déterminer l'emplacement et l'ordre des sites de restriction sur un fragment d'ADN. Les sites de restriction sont des séquences spécifiques d'une certaine longueur où une enzyme de restriction peut couper ou cliver l'ADN.
La cartographie des restrictions implique la digestion de l'ADN avec différentes enzymes de restriction, suivie de l'analyse de la taille des fragments résultants par électrophorèse sur gel d'agarose. Les tailles des fragments sont ensuite utilisées pour déduire l'emplacement et l'ordre relatifs des sites de restriction sur le fragment d'ADN.
Cette technique est utile dans divers domaines, tels que la génétique humaine, la génomique, la biologie moléculaire et la biotechnologie, pour étudier la structure et l'organisation de l'ADN, identifier les mutations et les réarrangements chromosomiques, et caractériser les gènes et les régions régulatrices.
En résumé, la cartographie des restrictions est une méthode pour déterminer l'emplacement et l'ordre des sites de restriction sur un fragment d'ADN en utilisant des enzymes de restriction et l'analyse de la taille des fragments résultants.
Une séquence nucléotidique est l'ordre spécifique et linéaire d'une série de nucléotides dans une molécule d'acide nucléique, comme l'ADN ou l'ARN. Chaque nucléotide se compose d'un sucre (désoxyribose dans le cas de l'ADN et ribose dans le cas de l'ARN), d'un groupe phosphate et d'une base azotée. Les bases azotées peuvent être adénine (A), guanine (G), cytosine (C) et thymine (T) dans l'ADN, tandis que dans l'ARN, la thymine est remplacée par l'uracile (U).
La séquence nucléotidique d'une molécule d'ADN ou d'ARN contient des informations génétiques cruciales qui déterminent les caractéristiques et les fonctions de tous les organismes vivants. La décodage de ces séquences, appelée génomique, est essentiel pour comprendre la biologie moléculaire, la médecine et la recherche biologique en général.
Je suis désolé, mais il semble y avoir une petite erreur dans votre question. Deoxyribonuclease (DNase) n'est pas spécifiquement associée à la restriction enzyme EcoRI. DNases sont des enzymes qui coupent l'acide désoxyribonucléique (ADN) en différents endroits.
Cependant, pour clarifier, EcoRI est une enzyme de restriction spécifique qui coupe l'ADN à des séquences particulières. Elle est isolée de la bactérie Escherichia coli et reconnait et clive la séquence GAATTC dans l'ADN.
Donc, pour répondre à votre question, Deoxyribonuclease EcoRI n'est pas une définition médicale établie car EcoRI n'est pas une DNase. Ce sont deux types d'enzymes différents qui ont des fonctions différentes dans la biologie moléculaire.
L'ADN (acide désoxyribonucléique) est une molécule complexe qui contient les instructions génétiques utilisées dans le développement et la fonction de tous les organismes vivants connus et certains virus. L'ADN est un long polymère d'unités simples appelées nucléotides, avec des séquences de ces nucléotides qui forment des gènes. Ces gènes sont responsables de la synthèse des protéines et de la régulation des processus cellulaires.
L'ADN est organisé en une double hélice, où deux chaînes polynucléotidiques s'enroulent autour d'un axe commun. Les chaînes sont maintenues ensemble par des liaisons hydrogène entre les bases complémentaires : adénine (A) avec thymine (T), et guanine (G) avec cytosine (C).
L'ADN est présent dans le noyau de la cellule, ainsi que dans certaines mitochondries et chloroplastes. Il joue un rôle crucial dans l'hérédité, la variation génétique et l'évolution des espèces. Les mutations de l'ADN peuvent entraîner des changements dans les gènes qui peuvent avoir des conséquences sur le fonctionnement normal de la cellule et être associées à des maladies génétiques ou cancéreuses.
L'hybridation d'acides nucléiques est un processus dans lequel deux molécules d'acides nucléiques, généralement une molécule d'ADN et une molécule d'ARN ou deux molécules d'ADN complémentaires, s'apparient de manière spécifique par des interactions hydrogène entre leurs bases nucléotidiques correspondantes. Ce processus est largement utilisé en biologie moléculaire et en génétique pour identifier, localiser et manipuler des séquences d'ADN ou d'ARN spécifiques.
L'hybridation a lieu lorsque les deux brins d'acides nucléiques sont mélangés et portés à des températures et des concentrations de sel optimales pour permettre la formation de paires de bases complémentaires. Les conditions d'hybridation doivent être soigneusement contrôlées pour assurer la spécificité et la stabilité de l'appariement des bases.
L'hybridation d'acides nucléiques est une technique sensible et fiable qui peut être utilisée pour détecter la présence de séquences d'ADN ou d'ARN spécifiques dans un échantillon, pour mesurer l'abondance relative de ces séquences, et pour analyser les relations évolutives entre différentes espèces ou populations. Elle est largement utilisée dans la recherche en génétique, en médecine, en biologie moléculaire, en agriculture et dans d'autres domaines où l'identification et l'analyse de séquences d'acides nucléiques sont importantes.
Les enzymes de restriction-modification d'ADN sont des systèmes enzymatiques présents dans les bactéries et les archées qui fournissent une défense contre l'infection par des virus bactériens (bactériophages). Elles fonctionnent en protégeant l'ADN de l'hôte en coupant l'ADN étranger invasif, tout en laissant intact l'ADN de l'hôte.
Ce système est composé de deux types d'enzymes : les endonucléases de restriction et les méthyltransférases d'ADN. Les endonucléases de restriction coupent l'ADN étranger en reconnaissant des séquences spécifiques d'ADN, appelées sites de restriction. En revanche, les méthyltransférases d'ADN méthylent ces mêmes séquences sur l'ADN de l'hôte, ce qui empêche la coupure par les endonucléases de restriction.
Ces enzymes sont largement utilisées dans la recherche biologique pour des applications telles que le clonage moléculaire et l'analyse de l'ADN. Elles sont classées selon leur cofacteur, leur spécificité de reconnaissance du site et leur activité d'endonucléase. Les enzymes de restriction les plus couramment utilisées sont les enzymes de type II, qui coupent l'ADN au milieu de leur site de reconnaissance.
Les plasmides sont des molécules d'ADN extrachromosomiques double brin, circulaires et autonomes qui se répliquent indépendamment du chromosome dans les bactéries. Ils peuvent également être trouvés dans certains archées et organismes eucaryotes. Les plasmides sont souvent associés à des fonctions particulières telles que la résistance aux antibiotiques, la dégradation des molécules organiques ou la production de toxines. Ils peuvent être transférés entre bactéries par conjugaison, transformation ou transduction, ce qui en fait des vecteurs importants pour l'échange de gènes et la propagation de caractères phénotypiques dans les populations bactériennes. Les plasmides ont une grande importance en biotechnologie et en génie génétique en raison de leur utilité en tant que vecteurs clonage et d'expression des gènes.
L'ADN viral fait référence à l'acide désoxyribonucléique (ADN) qui est présent dans le génome des virus. Le génome d'un virus peut être composé d'ADN ou d'ARN (acide ribonucléique). Les virus à ADN ont leur matériel génétique sous forme d'ADN, soit en double brin (dsDNA), soit en simple brin (ssDNA).
Les virus à ADN peuvent infecter les cellules humaines et utiliser le mécanisme de réplication de la cellule hôte pour se multiplier. Certains virus à ADN peuvent s'intégrer dans le génome de la cellule hôte et devenir partie intégrante du matériel génétique de la cellule. Cela peut entraîner des changements permanents dans les cellules infectées et peut contribuer au développement de certaines maladies, telles que le cancer.
Il est important de noter que la présence d'ADN viral dans l'organisme ne signifie pas nécessairement qu'une personne est malade ou présentera des symptômes. Cependant, dans certains cas, l'ADN viral peut entraîner une infection active et provoquer des maladies.
La electrophorèse sur gel d'agarose est un type de méthode d'électrophorèse utilisée dans la séparation et l'analyse des macromolécules, en particulier l'ADN, l'ARN et les protéines. Dans cette technique, une solution d'agarose est préparée et versée dans un moule pour former un gel. Une fois le gel solidifié, il est placé dans un réservoir rempli d'une solution tampon et des échantillons contenant les macromolécules à séparer sont appliqués sur le gel.
Lorsque le courant électrique est appliqué, les molécules chargées migrent vers l'anode ou la cathode en fonction de leur charge et de leur poids moléculaire. Les molécules plus petites et/ou moins chargées se déplacent plus rapidement que les molécules plus grandes et/ou plus chargées, ce qui entraîne une séparation des macromolécules en fonction de leur taille et de leur charge.
La electrophorèse sur gel d'agarose est souvent utilisée dans la recherche en biologie moléculaire pour analyser la taille et la pureté des fragments d'ADN ou d'ARN, tels que ceux obtenus par PCR ou digestion enzymatique. Les gels peuvent être colorés avec des colorants tels que le bleu de bromophénol ou l'éthidium bromure pour faciliter la visualisation et l'analyse des bandes de macromolécules séparées.
En résumé, la electrophorèse sur gel d'agarose est une technique couramment utilisée en biologie moléculaire pour séparer et analyser les macromolécules telles que l'ADN, l'ARN et les protéines en fonction de leur taille et de leur charge.
La Déoxyribonuclease BamHI est une enzyme de restriction spécifique qui est isolée à partir du bactérie Bacillus amyloliquefaciens. Elle reconnait et clive spécifiquement l'ADN double brin au niveau du site palindromique 5'-G|GATCC-3'. Cette enzyme est souvent utilisée dans les laboratoires de recherche en biologie moléculaire pour manipuler l'ADN, par exemple pour couper des fragments d'ADN à des endroits spécifiques ou pour éliminer des fragments d'ADN indésirables.
Il est important de noter que les enzymes de restriction comme BamHI sont souvent utilisées dans des applications de génie génétique, telles que le clonage moléculaire et l'analyse de l'expression génique. Cependant, elles doivent être manipulées avec soin pour éviter toute contamination croisée entre les échantillons et pour assurer la stérilité des équipements et des surfaces de travail.
La Déoxyribonuclease HindIII est une endonucléase de restriction qui coupe l'ADN à des sites spécifiques. Elle est isolée à partir de la bactérie Haemophilus influenzae et reconnait et clive le motif palindromique AAGCTT dans l'ADN double brin. Cette enzyme est souvent utilisée en biologie moléculaire pour créer des fragments d'ADN restreints, qui peuvent être séparés par électrophorèse sur gel et analysés pour étudier la structure et la fonction du génome.
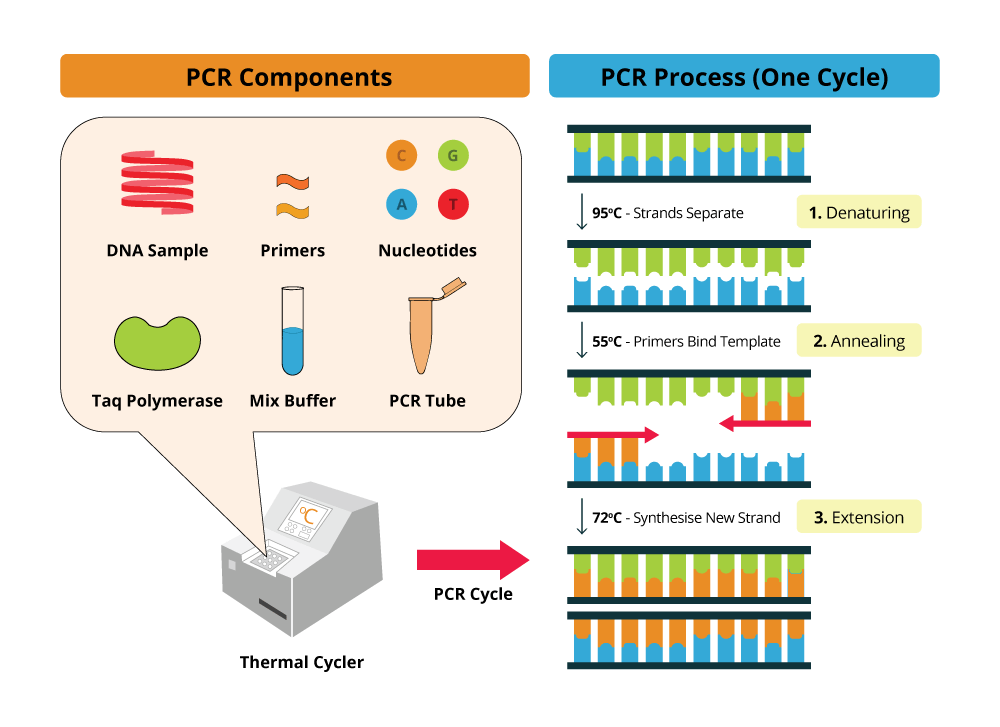
La réaction de polymérisation en chaîne est un processus chimique au cours duquel des molécules de monomères réagissent ensemble pour former de longues chaînes de polymères. Ce type de réaction se caractérise par une vitesse de réaction rapide et une exothermie, ce qui signifie qu'elle dégage de la chaleur.
Dans le contexte médical, les réactions de polymérisation en chaîne sont importantes dans la production de matériaux biomédicaux tels que les implants et les dispositifs médicaux. Par exemple, certains types de plastiques et de résines utilisés dans les équipements médicaux sont produits par polymérisation en chaîne.
Cependant, il est important de noter que certaines réactions de polymérisation en chaîne peuvent également être impliquées dans des processus pathologiques, tels que la formation de plaques amyloïdes dans les maladies neurodégénératives telles que la maladie d'Alzheimer. Dans ces cas, les protéines se polymérisent en chaînes anormales qui s'accumulent et endommagent les tissus cérébraux.
L'ADN ribosomal (rDNA) est un type spécifique d'acide désoxyribonucléique qui code pour les ARN ribosomaux, qui sont des composants structurels et fonctionnels essentiels des ribosomes. Les ribosomes sont des complexes macromoléculaires trouvés dans les cellules de tous les organismes vivants et jouent un rôle crucial dans la synthèse des protéines en facilitant le processus de traduction de l'ARN messager (ARNm) en chaînes polypeptidiques.
Les gènes rDNA sont généralement organisés en plusieurs centaines à quelques milliers de copies dans le génome d'un organisme donné, ce qui permet une expression abondante et régulée des ARN ribosomaux nécessaires pour soutenir la synthèse constante des protéines. Les séquences rDNA sont souvent utilisées comme marqueurs dans l'étude de l'évolution moléculaire, de la systématique et de la biodiversité en raison de leur conservation relative entre les espèces et de leur variabilité au sein des populations.
Les ARN ribosomaux sont classés en deux catégories principales : les ARN ribosomaux 18S, 5,8S et 28S (eucaryotes) ou 16S et 23S (procaryotes), qui composent le noyau des ribosomes et sont directement impliqués dans la catalyse de la formation des liaisons peptidiques pendant la traduction, et les ARN ribosomaux 5S, qui sont associés aux sous-unités ribosomales mineures.
En résumé, l'ADN ribosomal est un type d'acide désoxyribonucléique qui code pour les ARN ribosomaux essentiels à la synthèse des protéines dans les cellules de tous les organismes vivants. Les gènes rDNA sont souvent utilisés comme marqueurs dans l'étude de l'évolution moléculaire, de la systématique et de la biodiversité en raison de leur conservation relative entre les espèces et de leur variabilité au sein des populations.
Les données de séquence moléculaire se réfèrent aux informations génétiques ou protéomiques qui décrivent l'ordre des unités constitutives d'une molécule biologique spécifique. Dans le contexte de la génétique, cela peut inclure les séquences d'ADN ou d'ARN, qui sont composées d'une série de nucléotides (adénine, thymine, guanine et cytosine pour l'ADN; adénine, uracile, guanine et cytosine pour l'ARN). Dans le contexte de la protéomique, cela peut inclure la séquence d'acides aminés qui composent une protéine.
Ces données sont cruciales dans divers domaines de la recherche biologique et médicale, y compris la génétique, la biologie moléculaire, la médecine personnalisée, la pharmacologie et la pathologie. Elles peuvent aider à identifier des mutations ou des variations spécifiques qui peuvent être associées à des maladies particulières, à prédire la structure et la fonction des protéines, à développer de nouveaux médicaments ciblés, et à comprendre l'évolution et la diversité biologique.
Les technologies modernes telles que le séquençage de nouvelle génération (NGS) ont rendu possible l'acquisition rapide et économique de vastes quantités de données de séquence moléculaire, ce qui a révolutionné ces domaines de recherche. Cependant, l'interprétation et l'analyse de ces données restent un défi important, nécessitant des méthodes bioinformatiques sophistiquées et une expertise spécialisée.
La restriction calorique est une stratégie diététique dans laquelle l'apport énergétique est volontairement réduit en dessous du niveau d'entretien de l'individu. Cela peut être accompli en réduisant la quantité de nourriture consommée ou en choisissant des aliments à faible densité énergétique. La restriction calorique peut être utilisée dans le traitement de l'obésité et d'autres conditions liées à l'alimentation, telles que le syndrome métabolique et le diabète de type 2. Il est important de noter que la restriction calorique devrait toujours être supervisée par un professionnel de la santé pour assurer une alimentation équilibrée et suffisamment nutritive.
Une "coupure de l'ADN" fait référence à une modification de la structure de l'acide désoxyribonucléique (ADN) provoquée par des agents physiques ou chimiques qui clivent, brisent ou séparent les deux brins de la molécule d'ADN. Ce processus est souvent le résultat d'une enzyme de restriction, d'un dommage oxydatif, d'une exposition aux rayonnements ionisants ou à d'autres agents mutagènes. Les cassures de l'ADN peuvent entraîner des altérations du génome, ce qui peut conduire à des maladies, au vieillissement prématuré ou au développement de cellules cancéreuses si elles ne sont pas réparées correctement par les mécanismes de réparation de l'ADN de la cellule.
Les coupures simples de l'ADN se produisent lorsqu'un seul brin d'ADN est clivé, tandis que les coupures doubles de l'ADN impliquent la rupture des deux brins d'ADN. Les coupures doubles sont considérées comme plus préjudiciables car elles peuvent entraver la réplication et la transcription de l'ADN, ce qui peut entraîner une instabilité génomique et une mort cellulaire.
Les coupures de l'ADN sont des événements courants dans les cellules et sont généralement réparées par des mécanismes de réparation de l'ADN hautement régulés, tels que la recombinaison homologue ou la jonction non homologue d'extrémités. Cependant, en cas de dysfonctionnement de ces mécanismes de réparation, les coupures de l'ADN peuvent persister et entraîner des conséquences néfastes pour la cellule et l'organisme dans son ensemble.
Le clonage moléculaire est une technique de laboratoire qui permet de créer plusieurs copies identiques d'un fragment d'ADN spécifique. Cette méthode implique l'utilisation de divers outils et processus moléculaires, tels que des enzymes de restriction, des ligases, des vecteurs d'ADN (comme des plasmides ou des phages) et des hôtes cellulaires appropriés.
Le fragment d'ADN à cloner est d'abord coupé de sa source originale en utilisant des enzymes de restriction, qui reconnaissent et coupent l'ADN à des séquences spécifiques. Le vecteur d'ADN est également coupé en utilisant les mêmes enzymes de restriction pour créer des extrémités compatibles avec le fragment d'ADN cible. Les deux sont ensuite mélangés dans une réaction de ligation, où une ligase (une enzyme qui joint les extrémités de l'ADN) est utilisée pour fusionner le fragment d'ADN et le vecteur ensemble.
Le produit final de cette réaction est un nouvel ADN hybride, composé du vecteur et du fragment d'ADN cloné. Ce nouvel ADN est ensuite introduit dans un hôte cellulaire approprié (comme une bactérie ou une levure), où il peut se répliquer et produire de nombreuses copies identiques du fragment d'ADN original.
Le clonage moléculaire est largement utilisé en recherche biologique pour étudier la fonction des gènes, produire des protéines recombinantes à grande échelle, et développer des tests diagnostiques et thérapeutiques.
Une empreinte génétique, également appelée profilage ADN ou analyse de l'ADN, est une méthode d'identification individuelle basée sur l'analyse des séquences répétitives uniques et variables dans l'ADN. Cela implique l'examen des régions non codantes du génome, appelées marqueurs génétiques, qui se trouvent dans presque tous les noyaux cellulaires. Les modèles de ces marqueurs varient d'une personne à l'autre (sauf dans le cas de jumeaux identiques), ce qui permet une identification précise et fiable d'un individu.
L'empreinte génétique est largement utilisée en médecine légale pour aider à identifier des suspects ou des victimes dans les affaires criminelles, ainsi que dans la recherche médicale et biologique pour étudier l'hérédité, la parenté et d'autres caractéristiques génétiques. Il est important de noter que le processus d'obtention d'une empreinte génétique nécessite généralement un échantillon de cellules, comme du sang, de la salive ou des cheveux, et doit être effectué dans des laboratoires spécialisés avec un équipement approprié et des techniciens qualifiés.
En termes simples, un gène est une séquence d'acide désoxyribonucléique (ADN) qui contient les instructions pour la production de molécules appelées protéines. Les protéines sont des composants fondamentaux des cellules et remplissent une multitude de fonctions vitales, telles que la structure, la régulation, la signalisation et les catalyseurs des réactions chimiques dans le corps.
Les gènes représentent environ 1 à 5 % du génome humain complet. Chaque gène est une unité discrète d'hérédité qui code généralement pour une protéine spécifique, bien que certains gènes fournissent des instructions pour produire des ARN non codants, qui ont divers rôles dans la régulation de l'expression génétique et d'autres processus cellulaires.
Les mutations ou variations dans les séquences d'ADN des gènes peuvent entraîner des changements dans les protéines qu'ils codent, ce qui peut conduire à des maladies génétiques ou prédisposer une personne à certaines conditions médicales. Par conséquent, la compréhension des gènes et de leur fonction est essentielle pour la recherche biomédicale et les applications cliniques telles que le diagnostic, le traitement et la médecine personnalisée.
Le Southern Blot est une méthode de laboratoire utilisée en biologie moléculaire pour détecter et identifier des séquences d'ADN spécifiques dans un échantillon d'acide désoxyribonucléique (ADN). Cette technique a été nommée d'après son inventeur, le scientifique britannique Edwin Southern.
Le processus implique plusieurs étapes :
1. L'échantillon d'ADN est d'abord coupé en fragments de taille égale à l'aide d'une enzyme de restriction.
2. Ces fragments sont ensuite séparés par électrophorèse sur gel d'agarose, une méthode qui permet de les organiser selon leur longueur.
3. Le gel est ensuite transféré sur une membrane de nitrocellulose ou de nylon, créant ainsi un "blot" du patron de bandes des fragments d'ADN.
4. La membrane est alors exposée à une sonde d'ADN marquée, qui se lie spécifiquement aux séquences d'intérêt.
5. Enfin, l'emplacement des bandes sur la membrane est détecté par autoradiographie ou par d'autres méthodes de visualisation, révélant ainsi la présence et la quantité relative des séquences d'ADN cibles dans l'échantillon.
Le Southern Blot est une technique sensible et spécifique qui permet non seulement de détecter des séquences d'ADN particulières, mais aussi de distinguer des variantes subtiles telles que les mutations ponctuelles ou les polymorphismes. Il s'agit d'une méthode fondamentale en biologie moléculaire et en génétique, largement utilisée dans la recherche et le diagnostic de maladies génétiques, ainsi que dans l'analyse des gènes et des génomes.
Escherichia coli (E. coli) est une bactérie gram-negative, anaérobie facultative, en forme de bâtonnet, appartenant à la famille des Enterobacteriaceae. Elle est souvent trouvée dans le tractus gastro-intestinal inférieur des humains et des animaux warms blooded. La plupart des souches d'E. coli sont inoffensives et font partie de la flore intestinale normale, mais certaines souches peuvent causer des maladies graves telles que des infections urinaires, des méningites, des septicémies et des gastro-entérites. La souche la plus courante responsable d'infections diarrhéiques est E. coli entérotoxigénique (ETEC). Une autre souche préoccupante est E. coli producteur de shigatoxines (STEC), y compris la souche hautement virulente O157:H7, qui peut provoquer des colites hémorragiques et le syndrome hémolytique et urémique. Les infections à E. coli sont généralement traitées avec des antibiotiques, mais certaines souches sont résistantes aux médicaments couramment utilisés.
Les techniques de typage bactérien sont des méthodes utilisées en microbiologie pour identifier et clasifier les bactéries au-delà du niveau de genre et d'espèce. Elles permettent de distinguer des souches bactériennes similaires mais pas identiques, ce qui est crucial dans la surveillance des maladies infectieuses, l'épidémiologie, le contrôle de la contamination et la recherche.
Plusieurs techniques sont couramment utilisées pour le typage bactérien, y compris :
1. **Sérotypage** : Cette méthode consiste à classer les bactéries en fonction des antigènes présents à leur surface. Les antigènes sont des molécules reconnues par le système immunitaire et qui peuvent déclencher une réponse immune spécifique. Dans le cadre du sérotypage, on utilise des sérums contenant des anticorps spécifiques pour identifier les différents types d'antigènes présents à la surface des bactéries.
2. **Phagotypage** : Cette technique est semblable au sérotypage, mais elle utilise des phages (des virus qui infectent les bactéries) au lieu d'anticorps pour identifier les souches bactériennes. Les phages se lient aux récepteurs spécifiques situés à la surface des bactéries, ce qui permet de distinguer différents types de bactéries.
3. **Bactériophagage** : Cette méthode consiste à utiliser des bactériophages pour infecter et tuer des bactéries spécifiques. Elle est souvent utilisée dans le contrôle de la contamination, en particulier dans l'industrie alimentaire.
4. **Profilage biochimique** : Cette technique consiste à analyser les profils métaboliques des bactéries pour les distinguer. Les bactéries sont incubées dans des milieux contenant différents nutriments et substrats, et on observe leur capacité à dégrader ou à utiliser ces substances pour produire de l'énergie.
5. **Analyse génétique** : Cette méthode consiste à analyser l'ADN des bactéries pour identifier les différences entre les souches. Les techniques d'analyse génétique comprennent la PCR (réaction en chaîne par polymérase), le séquençage de l'ADN et l'hybridation de l'ADN.
6. **Protéomique** : Cette technique consiste à analyser les protéines produites par les bactéries pour identifier les différences entre les souches. Les techniques de protéomique comprennent la spectrométrie de masse et l'analyse des profils d'expression des gènes.
En combinant ces différentes méthodes, il est possible de distinguer et d'identifier avec précision les différents types de bactéries, ce qui est important pour la recherche médicale, la sécurité alimentaire et la lutte contre les maladies infectieuses.
L'ADN recombinant est une technologie de génie génétique qui consiste à combiner des molécules d'ADN de différentes sources pour créer une nouvelle séquence d'ADN. Cette technique permet aux scientifiques de manipuler et de modifier l'information génétique pour diverses applications, telles que la production de protéines thérapeutiques, la recherche biologique, l'amélioration des cultures agricoles et la médecine personnalisée.
L'ADN recombinant est créé en laboratoire en utilisant des enzymes de restriction pour couper les molécules d'ADN à des endroits spécifiques, ce qui permet de séparer et d'échanger des segments d'ADN entre eux. Les fragments d'ADN peuvent ensuite être liés ensemble à l'aide d'enzymes appelées ligases pour former une nouvelle molécule d'ADN recombinant.
Cette technologie a révolutionné la biologie et la médecine en permettant de mieux comprendre les gènes et leur fonction, ainsi que de développer de nouveaux traitements pour les maladies génétiques et infectieuses. Cependant, l'utilisation de l'ADN recombinant soulève également des préoccupations éthiques et réglementaires en raison de son potentiel de modification irréversible du génome humain et non humain.
Je suis désolé, mais la phrase que vous avez demandée à définir ne semble pas être une expression ou un terme médical standard. "Spécificité Espèce" ne donne aucun résultat pertinent dans les contextes médicaux ou scientifiques.
Si vous cherchez des informations sur la spécificité en général dans le contexte médical, cela fait référence à la capacité d'un test diagnostique à correctement identifier les individus sans une certaine condition. En d'autres termes, la spécificité est le rapport entre le nombre de vrais négatifs et le total des personnes négatives (saines) dans une population donnée.
Si vous cherchiez des informations sur la taxonomie biologique ou l'identification des espèces, "spécificité d'espèce" pourrait faire référence à des caractéristiques uniques qui définissent et différencient une espèce donnée des autres.
Si vous pouviez me fournir plus de contexte ou clarifier votre question, je serais heureux de vous aider davantage.
La cartographie chromosomique est une discipline de la génétique qui consiste à déterminer l'emplacement et l'ordre relatif des gènes et des marqueurs moléculaires sur les chromosomes. Cette technique utilise généralement des méthodes de laboratoire pour analyser l'ADN, comme la polymerase chain reaction (PCR) et la Southern blotting, ainsi que des outils d'informatique pour visualiser et interpréter les données.
La cartographie chromosomique est un outil important dans la recherche génétique, car elle permet aux scientifiques de comprendre comment les gènes sont organisés sur les chromosomes et comment ils interagissent entre eux. Cela peut aider à identifier les gènes responsables de certaines maladies héréditaires et à développer des traitements pour ces conditions.
Il existe deux types de cartographie chromosomique : la cartographie physique et la cartographie génétique. La cartographie physique consiste à déterminer l'emplacement exact d'un gène ou d'un marqueur sur un chromosome en termes de distance physique, exprimée en nucléotides. La cartographie génétique, quant à elle, consiste à déterminer l'ordre relatif des gènes et des marqueurs sur un chromosome en fonction de la fréquence de recombinaison entre eux lors de la méiose.
En résumé, la cartographie chromosomique est une technique utilisée pour déterminer l'emplacement et l'ordre relatif des gènes et des marqueurs moléculaires sur les chromosomes, ce qui permet aux scientifiques de mieux comprendre comment les gènes sont organisés et interagissent entre eux.
La electrophoresis, gel, pulsed-field (électrophorèse en gels à champ pulsé) est une technique de séparation et d'analyse des macromolécules, telles que l'ADN, l'ARN et les protéines, en fonction de leur taille et de leur forme. Cette méthode utilise un gel de polyacrylamide ou d'agarose comme matrice de séparation et des champs électriques alternatifs à des angles multiples pour fractionner les macromolécules en fonction de leur mobilité différentielle dans le gel.
Dans cette technique, l'échantillon contenant les molécules d'intérêt est appliqué sur une extrémité du gel et un courant électrique est appliqué. Les macromolécules migrent à des vitesses différentes en fonction de leur taille et de leur charge, ce qui entraîne leur séparation dans le gel. Après une certaine période de temps, le champ électrique est inversé ou modifié à un angle différent, provoquant ainsi la réorientation des macromolécules et un nouveau cycle de séparation. Ce processus est répété plusieurs fois, ce qui permet d'obtenir une séparation plus efficace et précise des molécules en fonction de leur taille et de leur forme.
L'électrophorèse en gels à champ pulsé est particulièrement utile pour la séparation et l'analyse d'ADN de grande taille, tels que les chromosomes ou les fragments d'ADN génomique entiers, qui sont difficiles à séparer par des méthodes conventionnelles d'électrophorèse en gels. Cette technique est largement utilisée dans la recherche en génétique et en biologie moléculaire pour l'analyse de mutations, la cartographie génomique, l'assemblage de séquences d'ADN et l'identification de pathogènes.
Je suis désolé, mais Olivomycine n'est pas un terme reconnu dans le domaine médical ou pharmacologique. Il pourrait s'agir d'une substance inconnue dans ce contexte. Si vous pouviez me fournir plus de détails ou de clarification, je serais heureux de vous fournir plus d'informations pertinentes.
Cependant, Olivomycine est un groupe de composés naturels isolés de certaines souches de champignons du genre Streptomyces, qui ont démontré des activités antimicrobiennes et antitumorales dans des études de laboratoire. Mais il n'est pas largement utilisé ou reconnu en médecine clinique.
Le polymorphisme génétique fait référence à la présence de plus d'un allèle pour un gène donné dans une population, ce qui entraîne une variabilité génétique. Il s'agit d'une variation normale et courante du matériel génétique chez les êtres humains et d'autres organismes. Ce polymorphisme peut se produire en raison de divers types de mutations, telles que des substitutions de base, des insertions ou des délétions d'une ou plusieurs paires de bases dans le gène.
Les polymorphismes génétiques peuvent avoir différents effets sur la fonction du gène et de son produit protéique associé. Dans certains cas, ils peuvent ne pas affecter la fonction du tout, tandis que dans d'autres, ils peuvent entraîner des changements mineurs ou même majeurs dans la structure et la fonction de la protéine. Ces variations peuvent contribuer à la diversité phénotypique observée au sein d'une population, y compris la susceptibilité aux maladies et les réponses aux traitements médicaux.
Les polymorphismes génétiques sont souvent utilisés en médecine et en recherche biomédicale pour identifier des marqueurs génétiques associés à des maladies ou à des traits spécifiques. Ils peuvent également être utiles dans l'identification individuelle, la parenté et les études d'ascendance.
L'ARN ribosomique 16S est une molécule d'acide ribonucléique (ARN) qui fait partie du petit ribosome dans les cellules vivantes. Les ribosomes sont des complexes protéiques et ARN qui jouent un rôle central dans la synthèse des protéines.
L'ARN ribosomique 16S est spécifiquement utilisé en biologie moléculaire pour identifier et classer les bactéries. Il s'agit d'un ARN conservé qui contient des séquences régionales variables qui peuvent être utilisées pour distinguer différentes espèces bactériennes.
En particulier, la région hypervariable de l'ARN ribosomique 16S est souvent ciblée pour l'amplification par PCR et la séquençage dans les études de microbiologie moléculaire. Ces techniques permettent aux chercheurs d'identifier et de caractériser rapidement et précisément les espèces bactériennes présentes dans un échantillon, ce qui est particulièrement utile dans des domaines tels que la médecine, l'agriculture et l'environnement.
Je suis désolé, mais il y a apparemment une petite erreur dans votre requête. Le terme correct devrait être "Deoxyribonuclease II" ou "DNase II". Il n'y a pas de sous-type spécifique connu sous le nom de "Hpaii" pour cette enzyme.
Maintenant, permettez-moi de vous fournir une définition médicale de la Deoxyribonuclease II (DNase II) :
La DNase II est une endonucléase qui clive les liaisons phosphodiester internes des molécules d'ADN, produisant des nucléotides et des oligonucléotides terminaux 3'-monophosphate. Elle est principalement active dans le noyau des cellules et joue un rôle important dans la dégradation de l'ADN au cours du processus de mort cellulaire programmée (apoptose). La DNase II est également présente dans les lysosomes, où elle contribue à la digestion des acides nucléiques provenant des matériaux phagocytés. Des dysfonctionnements de cette enzyme ont été associés à certaines maladies génétiques et auto-immunes.
La détermination de la séquence d'ADN est un processus de laboratoire qui consiste à déterminer l'ordre des nucléotides dans une molécule d'ADN. Les nucléotides sont les unités de base qui composent l'ADN, et chacun d'entre eux contient un des quatre composants différents appelés bases : adénine (A), guanine (G), cytosine (C) et thymine (T). La séquence spécifique de ces bases dans une molécule d'ADN fournit les instructions génétiques qui déterminent les caractéristiques héréditaires d'un organisme.
La détermination de la séquence d'ADN est généralement effectuée en utilisant des méthodes de séquençage de nouvelle génération (NGS), telles que le séquençage Illumina ou le séquençage Ion Torrent. Ces méthodes permettent de déterminer rapidement et à moindre coût la séquence d'un grand nombre de molécules d'ADN en parallèle, ce qui les rend utiles pour une variété d'applications, y compris l'identification des variations génétiques associées à des maladies humaines, la surveillance des agents pathogènes et la recherche biologique fondamentale.
Il est important de noter que la détermination de la séquence d'ADN ne fournit qu'une partie de l'information génétique d'un organisme. Pour comprendre pleinement les effets fonctionnels des variations génétiques, il est souvent nécessaire d'effectuer d'autres types d'analyses, tels que la détermination de l'expression des gènes et la caractérisation des interactions protéine-protéine.
Les gènes viraux se réfèrent aux segments d'ADN ou d'ARN qui composent le génome des virus et codent pour les protéines virales essentielles à leur réplication, infection et propagation. Ces gènes peuvent inclure ceux responsables de la production de capside (protéines structurelles formant l'enveloppe du virus), des enzymes de réplication et de transcription, ainsi que des protéines régulatrices impliquées dans le contrôle du cycle de vie viral.
Dans certains cas, les gènes viraux peuvent également coder pour des facteurs de pathogénicité, tels que des protéines qui suppriment la réponse immunitaire de l'hôte ou favorisent la libération et la transmission du virus. L'étude des gènes viraux est cruciale pour comprendre les mécanismes d'infection et de pathogenèse des virus, ce qui permet le développement de stratégies thérapeutiques et préventives ciblées contre ces agents infectieux.
Les gènes bactériens sont des segments d'ADN dans le génome d'une bactérie qui portent l'information génétique nécessaire à la synthèse des protéines et à d'autres fonctions cellulaires essentielles. Ils contrôlent des caractéristiques spécifiques telles que la croissance, la reproduction, la résistance aux antibiotiques et la production de toxines. Chaque gène a un code spécifique qui détermine la séquence d'acides aminés dans une protéine particulière. Les gènes bactériens peuvent être étudiés pour comprendre les mécanismes de la maladie, développer des thérapies et des vaccins, et améliorer les processus industriels tels que la production de médicaments et d'aliments.
L'ADN circulaire est une forme d'ADN (acide désoxyribonucléique) qui forme une boucle fermée sur elle-même, contrairement à l'ADN linéaire qui possède des extrémités libres. Cette structure se retrouve dans certains virus, plasmides bactériens et mitochondries.
Les plasmides bactériens sont des petits cercles d'ADN qui peuvent se répliquer indépendamment du chromosome bactérien et sont souvent responsables de la résistance aux antibiotiques chez les bactéries. Les mitochondries, organites présents dans les cellules eucaryotes, possèdent également leur propre ADN circulaire qui code pour certaines de leurs propres protéines.
L'ADN circulaire peut aussi être le résultat d'une réparation de l'ADN endommagé ou d'un processus de recombinaison génétique. Dans certains cas, des fragments d'ADN linéaire peuvent se rejoindre pour former une boucle fermée, créant ainsi une molécule d'ADN circulaire.
Les avantages de l'ADN circulaire comprennent sa stabilité structurelle et sa capacité à se répliquer indépendamment du chromosome hôte. Cependant, elle peut également présenter des inconvénients, tels que la susceptibilité à l'accumulation de mutations et la difficulté à réguler l'expression génétique.
Le génotype, dans le contexte de la génétique et de la médecine, se réfère à l'ensemble complet des gènes héréditaires d'un individu, y compris toutes les variations alléliques (formes alternatives d'un gène) qu'il a héritées de ses parents. Il s'agit essentiellement de la constitution génétique innée d'un organisme, qui détermine en grande partie ses caractéristiques et prédispositions biologiques.
Les différences génotypiques peuvent expliquer pourquoi certaines personnes sont plus susceptibles à certaines maladies ou répondent différemment aux traitements médicaux. Par exemple, dans le cas de la mucoviscidose, une maladie génétique potentiellement mortelle, les patients ont généralement un génotype particulier : deux copies du gène CFTR muté.
Il est important de noter que le génotype ne définit pas entièrement les caractéristiques d'un individu ; l'expression des gènes peut être influencée par divers facteurs environnementaux et épigénétiques, ce qui donne lieu à une grande variabilité phénotypique (manifestations observables des traits) même entre les personnes partageant le même génotype.
La « Type III Site-Specific Deoxyribonuclease » est une enzyme de restriction spécifique à un site qui coupe l'ADN double brin de manière asymétrique. Elle est également connue sous le nom de « Type III Restriction Endonuclease ». Cette enzyme est généralement trouvée dans les bactéries et elle fonctionne en conjugaison avec une méthylase modifiante de la methyl-transférase pour former un complexe d'enzymes de restriction.
Le site de reconnaissance spécifique pour la Type III Site-Specific Deoxyribonuclease est palindromique, ce qui signifie qu'il lit la même séquence de bases dans les deux directions. Cependant, contrairement à d'autres enzymes de restriction, cette enzyme ne coupe pas les brins d'ADN au milieu du site de reconnaissance. Au lieu de cela, elle coupe chaque brin à une distance définie mais différente du site de reconnaissance. Cette coupure asymétrique produit des extrémités cohésives ou à chevauchement qui peuvent se réassocier avant d'être complètement séparées.
La Type III Site-Specific Deoxyribonuclease joue un rôle important dans la défense de l'hôte contre les infections bactériophages en dégradant l'ADN étranger qui n'est pas méthylé au niveau du site de restriction. Elle participe ainsi à l'immunité de restriction, un système de défense propre aux bactéries.
ARN ribosomique (ARNr) est un type d'acide ribonucléique présent dans les ribosomes, qui sont des structures cellulaires impliquées dans la synthèse des protéines. Les ARNr jouent un rôle crucial dans la formation du site de liaison des acides aminés et de l'ARN messager pendant la traduction, qui est le processus par lequel l'information génétique contenue dans l'ADN est utilisée pour synthétiser des protéines.
Les ARNr sont transcrits à partir de gènes spécifiques dans le noyau cellulaire et subissent ensuite une série de modifications post-transcriptionnelles pour former des structures complexes et fonctionnelles. Ils se composent de plusieurs domaines qui s'associent pour former les sous-unités ribosomales majeures, à savoir la petite sous-unité 40S et la grande sous-unité 60S chez les eucaryotes.
Les ARNr sont des composants essentiels de la machinerie traductionnelle et leur structure et fonction ont été largement étudiées en raison de leur importance dans la synthèse des protéines. Des anomalies dans les gènes codant pour les ARNr peuvent entraîner des maladies génétiques rares, telles que les dysplasies osseuses et les troubles neurodégénératifs.
Les bactériophages, également connus sous le nom de phages, sont des virus qui infectent et se répliquent dans les bactéries. Ils sont extrêmement spécifiques aux souches bactériennes hôtes et ne infectent pas les cellules humaines ou animales. Les bactériophages peuvent être trouvés dans une variété d'environnements, y compris l'eau, le sol, les plantes et les animaux.
Les bactériophages se lient à des récepteurs spécifiques sur la surface de la bactérie hôte et insèrent leur matériel génétique dans la cellule bactérienne. Ils peuvent ensuite suivre l'un des deux parcours de réplication : le chemin lytique ou le chemin lysogénique.
Dans le chemin lytique, les bactériophages prennent le contrôle du métabolisme de la cellule hôte et utilisent ses ressources pour se répliquer. Ils produisent de nombreuses copies d'eux-mêmes et finissent par lyser (rompre) la membrane cellulaire bactérienne, libérant de nouvelles particules virales dans l'environnement.
Dans le chemin lysogénique, les bactériophages s'intègrent dans le génome de la bactérie hôte et restent inactifs pendant plusieurs générations. Lorsque certaines conditions sont remplies, comme une quantité adéquate de dommages à l'ADN de la bactérie hôte, les bactériophages peuvent devenir actifs, se répliquer et libérer de nouvelles particules virales.
Les bactériophages ont été découverts en 1915 par Frederick Twort au Royaume-Uni et Félix d'Hérelle en France. Ils ont été largement étudiés comme agents thérapeutiques potentiels contre les infections bactériennes, connus sous le nom de phagothérapie. Cependant, l'avènement des antibiotiques a éclipsé cette approche dans la plupart des pays développés. Avec la montée des bactéries résistantes aux antibiotiques, les bactériophages sont à nouveau considérés comme une alternative prometteuse pour traiter ces infections.
En génétique, une mutation est une modification permanente et héréditaire de la séquence nucléotidique d'un gène ou d'une région chromosomique. Elle peut entraîner des changements dans la structure et la fonction des protéines codées par ce gène, conduisant ainsi à une variété de phénotypes, allant de neutres (sans effet apparent) à délétères (causant des maladies génétiques). Les mutations peuvent être causées par des erreurs spontanées lors de la réplication de l'ADN, l'exposition à des agents mutagènes tels que les radiations ou certains produits chimiques, ou encore par des mécanismes de recombinaison génétique.
Il existe différents types de mutations, telles que les substitutions (remplacement d'un nucléotide par un autre), les délétions (suppression d'une ou plusieurs paires de bases) et les insertions (ajout d'une ou plusieurs paires de bases). Les conséquences des mutations sur la santé humaine peuvent être très variables, allant de maladies rares à des affections courantes telles que le cancer.
La sérotypie est un terme utilisé en microbiologie pour classer les bactéries ou autres agents pathogènes sur la base des antigènes somatiques (O) et capsulaires (K) qu'elles portent à leur surface. Ces antigènes sont des molécules spécifiques qui peuvent être reconnues par le système immunitaire et déclencher une réponse immunitaire.
Dans le cas de la sérotypie des bactéries, on utilise des sérums contenant des anticorps spécifiques pour identifier les différents types d'antigènes présents à la surface des bactéries. Les bactéries qui partagent les mêmes antigènes sont regroupées dans la même sérotype.
La sérotypie est particulièrement utile en médecine pour identifier et classifier certaines bactéries responsables de maladies infectieuses, telles que Escherichia coli, Salmonella, Shigella, Vibrio cholerae, et Streptococcus pneumoniae. Cette classification peut aider au diagnostic, à la surveillance épidémiologique, et à la prévention des maladies infectieuses.
Les sondes d'ADN sont des courtes séquences d'acides nucléiques (généralement d'ADN, mais parfois d'ARN) qui sont conçues pour rechercher et se lier spécifiquement à une séquence complémentaire particulière dans un échantillon d'ADN. Elles sont souvent utilisées en médecine et en biologie moléculaire pour identifier la présence de certains gènes ou mutations, détecter des agents pathogènes, ou analyser l'expression génétique.
Les sondes d'ADN peuvent être marquées avec des fluorophores ou d'autres étiquettes qui permettent de les détecter et de mesurer la force de leur liaison à la cible. Il existe différents types de sondes d'ADN, tels que les sondes linéaires, les sondes chevauchantes (overhang probes) et les sondes en grille (gridded probes), qui sont utilisées dans diverses techniques d'analyse, telles que la hybridation in situ, l'hybridation Southern, l'amplification en chaîne par polymérase (PCR) en temps réel et les microréseaux à ADN.
 Enzyme de restriction
Enzyme de restriction
Édition génomique
Liste de types d'ADN
Édition (biologie)
EcoRI
Analyse des fragments de restriction de l'ADN ribosomique amplifié
Sara Sawyer
BamHI
EcoRV
Méganucléase
Techniques de biologie moléculaire
ADN ligase
Daisy Dussoix
Stockage de données numériques sur ADN
Animal génétiquement modifié
Technologie Gateway
Recombinaison génétique
Génie génétique
ADN méthyltransférase
Saut sur le chromosome
Thermus aquaticus
APOBEC
5-Méthylcytosine
Southern blot
Séquençage shotgun
Sirtuine 1
Liste d'enzymes
Nicotinamide adénine dinucléotide
Craig Venter
Variantes de la PCR
Enzyme de restriction - Wikipedia
 Biologie moléculaire résumé lauriane par lauriane dani - Fichier PDF
Biologie moléculaire résumé lauriane par lauriane dani - Fichier PDF
 Plasmide. ADN extraction, clonage, séquençage
Plasmide. ADN extraction, clonage, séquençage
 Qu'est-ce que la Spiruline ? Origine, Bienfaits et Posologie | Dieti Natura
Qu'est-ce que la Spiruline ? Origine, Bienfaits et Posologie | Dieti Natura
 Substances nouvelles : lignes directrices pour la déclaration d'organismes - Canada.ca
Substances nouvelles : lignes directrices pour la déclaration d'organismes - Canada.ca
 Tout savoir sur le miel et ses bienfaits pour la santé | LaNutrition.fr
Tout savoir sur le miel et ses bienfaits pour la santé | LaNutrition.fr
 N-acétylcystéine : ses bienfaits et ses liens avec le glutathion
N-acétylcystéine : ses bienfaits et ses liens avec le glutathion
 Euchromatine
Euchromatine
Quel est le meilleur complément alimentaire anti-âge ?
 EUR-Lex - 52005SC0943 - EN - EUR-Lex
EUR-Lex - 52005SC0943 - EN - EUR-Lex
 L'empreinte parentale, un phénomène épigénétique essentiel pour la reproduction des plantes | médecine/sciences
L'empreinte parentale, un phénomène épigénétique essentiel pour la reproduction des plantes | médecine/sciences
 Generique Purim Pas Cher Descamps
Generique Purim Pas Cher Descamps
 Zinc - un oligo-élément vital - L'Apothicaire
Zinc - un oligo-élément vital - L'Apothicaire
 Causes du diabète et graisses saturées - L'argument végétalien
Causes du diabète et graisses saturées - L'argument végétalien
Poster peluches carie - BiOutils
 11 | sausio | 2023 | siapsau
11 | sausio | 2023 | siapsau
 Covid 19 'état des lieux' : les mensonges dévoilés dans une revue scientifique - Anthropo-logiques
Covid 19 'état des lieux' : les mensonges dévoilés dans une revue scientifique - Anthropo-logiques
 Test immunologique fécal (TIF) - Glossaire | Laboratoire, radiologie, sommeil et génétique | Biron
Test immunologique fécal (TIF) - Glossaire | Laboratoire, radiologie, sommeil et génétique | Biron
 Nouvelles des Brigades Anti-Graphène. Octobre 2021 | Xochipelli
Nouvelles des Brigades Anti-Graphène. Octobre 2021 | Xochipelli
 Search | African Index Medicus (AIM)
Search | African Index Medicus (AIM)
Cellules souches et R&D
 Electrophorèse - labconsult.be
Electrophorèse - labconsult.be
 Est-il préférable d'obtenir des nutriments à partir d'aliments ou de s - NADdirect
Est-il préférable d'obtenir des nutriments à partir d'aliments ou de s - NADdirect
 'Diabète, une addition salée' : un film d'Arte avec 'Big Pharma' ostensiblement dans le viseur - Science infuse site d...
'Diabète, une addition salée' : un film d'Arte avec 'Big Pharma' ostensiblement dans le viseur - Science infuse site d...
 DeCS
DeCS
DeCS
Cliquer pour imprimer
 Acides nucléiques - Cours de Biologie - F2School
Acides nucléiques - Cours de Biologie - F2School
De la conception du PRINS à son couronnement
Zygote
 Thermo Scientific™ BglII (10 U/µl) 10 U/μL, 2 500 U Thermo Scientific™ BglII (10 U/µl)
| Fisher Scientific
Thermo Scientific™ BglII (10 U/µl) 10 U/μL, 2 500 U Thermo Scientific™ BglII (10 U/µl)
| Fisher Scientific
Etats-Unis, Etat-policier : l'outil le plus cool de Big Brother
 Bienfaits et Dangerosité de la Niacine (Vitamine B3) - Par une Naturopathe
Bienfaits et Dangerosité de la Niacine (Vitamine B3) - Par une Naturopathe
 Du côté du web et de l'informatique agricole n° 18 du 14 septembre 2023
Du côté du web et de l'informatique agricole n° 18 du 14 septembre 2023
L'ADN8
- Pour éviter que l'enzyme de restriction ne coupe l'ADN de son propre génome, la bactérie fabrique aussi une deuxième enzyme appelée méthylase, qui reconnaît également le site de restriction. (wikipedia.org)
- Les enzymes de restrictions appartiennent à la classe des endonucléases, c'est-à-dire des enzymes capables de cliver les liaisons phosphodiester entre deux nucléotides à l'intérieur de la chaîne d'un acide nucléique, et plus spécifiquement appartiennent à la classe des endodésoxyribonucléases puisque spécifique à l'ADN. (wikipedia.org)
- Les enzymes de restriction sont capables de reconnaître spécifiquement et uniquement une courte séquence de l'ADN de 4 à 10 paires de bases, et de cliver les deux brins du duplex d'ADN au site reconnu. (wikipedia.org)
- Ces DNA polymérases fabriquent de l'ADN à partir d'une matrice d'ADN. (biodeug.com)
- Les DNAses sont des enzymes qui digèrent l'ADN. (biodeug.com)
- Ce sont des enzymes qui digèrent l'ADN double brin sur des séquences spécifiques. (biodeug.com)
- La T4 DNA ligase fonctionne sur de l'ADN double brin avec au moins, une liaison OH-Phosphore. (biodeug.com)
- 21 Une sirtuine, la SIRT1 (sir2 chez les mammifères) a été impliquée dans l'augmentation de la longévité associée à la restriction calorique 22 23 , grâce à une amélioration de la biogenèse mitochondriale et à la réparation de l'ADN. (doctonat.com)
L'enzyme de restriction4
- Lorsque le virus injecte son ADN dans la bactérie, celui-ci est coupé par l'enzyme de restriction au niveau de ses sites spécifiques. (wikipedia.org)
- Cette méthylation empêche la coupure par l'enzyme de restriction. (wikipedia.org)
- Cette intégration peut être faite, profitant de l'asymétrie créée par l'enzyme de restriction, en jouant sur l'homologie de séquence au site de clivage == site d'intégration. (wikipedia.org)
- Fragment reconnu par l'enzyme de restriction Eco R1 de E. coli. (biodeug.com)
Systems2
- Created from PDB 1RVA Smith HO, Nathans D, « Letter: A suggested nomenclature for bacterial host modification and restriction systems and their enzymes », J. Mol. (wikipedia.org)
- Systems consisting of two enzymes, a modification methylase and a restriction endonuclease. (bvsalud.org)
Specificity2
- They are closely related in their specificity and protect the DNA of a given bacterial species. (bvsalud.org)
- Specificity for the DNA target depends on the presence of a protospacer adjacent motif (PAM) sequence, a 2-6 nucleotide DNA sequence immediately following the sequence targeted by Cas9. (bvsalud.org)
D'une3
- Une enzyme de restriction est une protéine capable de couper un fragment d'ADN au niveau d'une séquence de nucléotides caractéristique appelée site de restriction. (wikipedia.org)
- Les enzymes de restriction peuvent être utilisées pour établir une carte génétique (appelée « carte de restriction ») d'une molécule d'ADN. (wikipedia.org)
- Les enzymes de type I et de type III reconnaissent une séquence d'ADN spécifique et coupent en un endroit aléatoire, d'une distance d'environ 1 000 paires de bases (pb) pour le type I et de 25 pb pour le type III plus loin que le site de restriction. (wikipedia.org)
Target3
- The methylase adds methyl groups to adenine or cytosine residues in the same target sequence that constitutes the restriction enzyme binding site. (bvsalud.org)
- The methylation renders the target site resistant to restriction, thereby protecting DNA against cleavage. (bvsalud.org)
- The nuclease module contains two enzymatic domains: RuvC, which cleaves non-target DNA strand, and an HNH nuclease domain, which cleaves the target strand. (bvsalud.org)
D'ADN1
- Les enzymes de restriction jouent un rôle crucial dans ce processus car elles permettent, en coupant le brin à un endroit précis et de manière asymétrique, l'intégration d'un brin d'ADN spécifique codant une protéine précise dans un plasmide dans le but de l'exprimer dans une bactérie. (wikipedia.org)
L'autre2
- Ce mécanisme de défense, appelé système de restriction/modification, associe systématiquement ces deux enzymes, l'une de coupure et l'autre de protection. (wikipedia.org)
- Cette synthèse fait intervenir l'autre sorte d'acides nucléiques : les RNA qui servent d'intermédiaires dans la circulation de l'information génétique du DNA aux protéines. (f2school.com)
Reconnaissent1
- Les enzymes de type II, les plus utilisées, reconnaissent une séquence spécifique et coupent en un endroit spécifique de cette séquence. (wikipedia.org)
Types1
- Ces enzymes de restriction donnent deux types de coupures : des coupures franches (au même niveau sur les deux brins) et des coupures à extrémités sortantes. (biodeug.com)
Unique1
- Unique en son genre, le DNA (RNA dans le cas de certains virus) fournit les directives pour sa propre réplication. (f2school.com)
Virus1
- Les enzymes de restriction produites par des bactéries constituent un mécanisme de défense contre les infections par les bactériophages, des virus spécifiques des bactéries. (wikipedia.org)